本文是以pawnyable里对内核漏洞缓解技术的文章security mechanism的学习、扩展。借鉴ctf-wiki里对内核漏洞缓解技术的分类方式,从异常检测、随机化、隔离、访问控制四个角度来学习内核中的防御机制。其中有部分文字从ctf-wiki 和 容器环境相关的内核漏洞缓解技术 直接拷贝的。
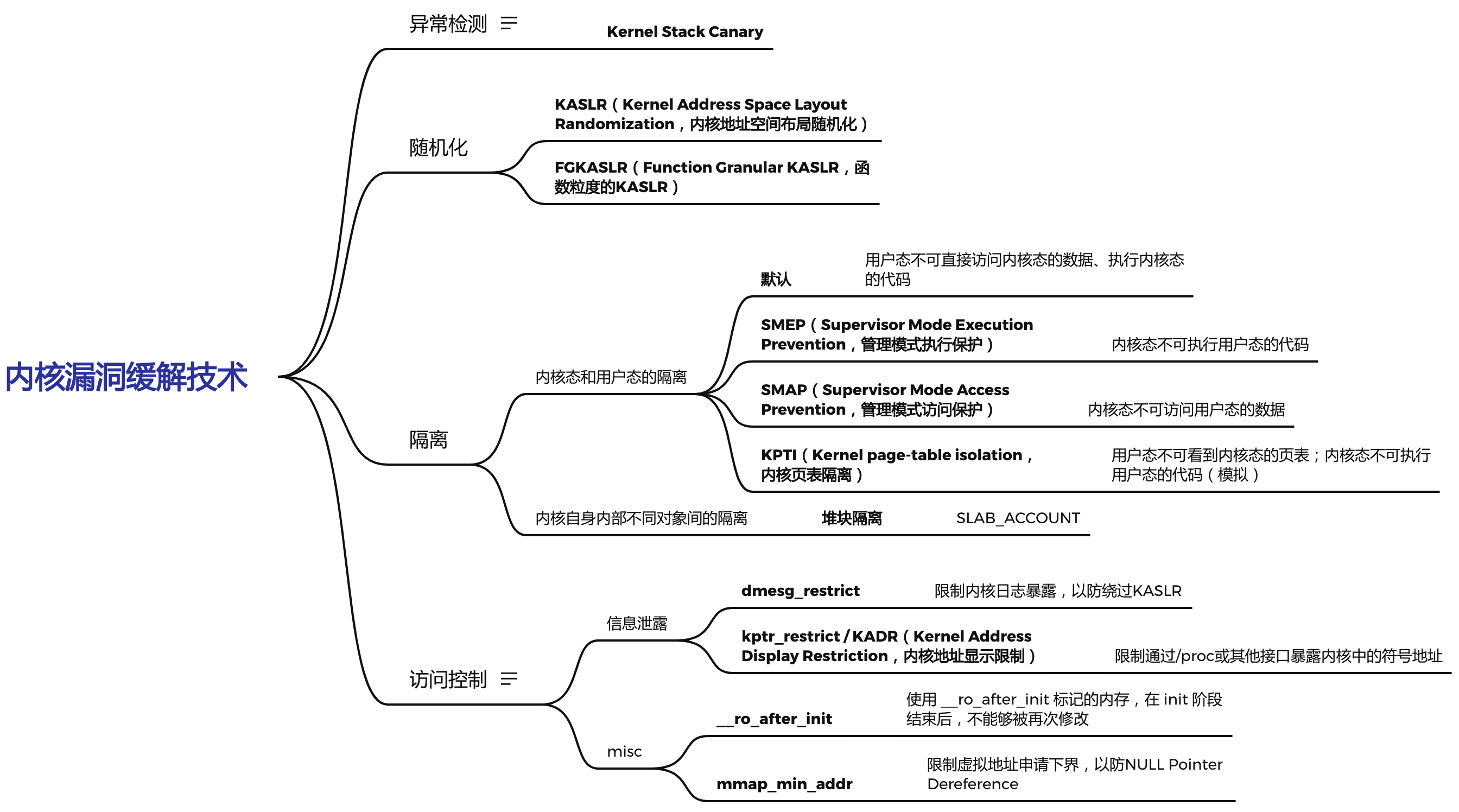
异常检测
Kernel Stack Canary
开始学内核pwn,那大概率已经学过用户态pwn了,就不介绍Canary了。顾名思义,此种技术就是内核里的Canary。
在 x86 架构中,同一个 task 中使用相同的 Canary。
查看开启状态
可以使用如下方式来检查是否开启了 Canary 保护:
checksec- 人工分析二进制文件,看函数中是否有保存和检查 Canary 的代码
开启
在编译内核时,设置 CONFIG_CC_STACKPROTECTOR 选项,来开启该保护。
关闭
关闭编译选项并重新编译内核,才可以关闭 Canary 保护。
绕过
根据 x86 架构下 Canary 实现的特点,只要泄漏了一次系统调用中的 Canary,同一 task 的其它系统调用中的 Canary 也就都被泄漏了。
随机化
KASLR
-
KASLR(Kernel Address Space Layout Randomization,内核地址空间布局随机化)
-
FGKASLR(Function Granular KASLR,函数粒度的KASLR)
KASLR就是内核中的ASLR。同样不详细介绍ASLR了,可自己去找例子熟悉ASLR。
/proc/sys/kernel/randomize_va_space值为0时,ASLR完全关闭;值为1时,仅仅对mmap基址、栈地址和VDSO页地址做随机化处理(共享库也将被加载到随机地址)
值为2时,在值为1的基础上,加上对堆的随机化。
查看开启状态
可以通过比较两次系统启动时的内核基址来判断KASLR是否开启,例如:
lzx@ubuntu:~/LKPWN/pawnyable$ sudo cat /proc/kallsyms | grep 'T startup_64'
ffffffff9be00000 T startup_64
lzx@ubuntu:~/LKPWN/pawnyable$ sudo init 6 # 重启
lzx@ubuntu:~/LKPWN/pawnyable$ sudo cat /proc/kallsyms | grep 'T startup_64'
ffffffffaa800000 T startup_64
从上述输出可以看到,第一次系统启动时内核基址是ffffffff9be00000,重启后变为ffffffffaa800000,说明KASLR开启。由于之前没有对KASLR的配置做过更改,所以也说明KASLR是默认开启的。
关闭
物理机/虚拟机
通过修改/etc/default/grub文件来达到目的。找到该文件中的GRUB_CMDLINE_LINUX配置项,在最后加上nokaslr,例如:
GRUB_CMDLINE_LINUX="find_preseed=/preseed.cfg auto noprompt priority=critical locale=en_US nokaslr"
然后执行更新即可:
lzx@ubuntu:~/LKPWN/pawnyable$ sudo update-grub
Sourcing file `/etc/default/grub'
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-5.4.0-135-generic
Found initrd image: /boot/initrd.img-5.4.0-135-generic
Found linux image: /boot/vmlinuz-5.4.0-90-generic
Found initrd image: /boot/initrd.img-5.4.0-90-generic
Found memtest86+ image: /boot/memtest86+.elf
Found memtest86+ image: /boot/memtest86+.bin
done
再次重启,可以发现地址已经变成了默认值ffffffff81000000,说明KASLR已经被关闭:
lzx@ubuntu:~/LKPWN/pawnyable$ sudo cat /proc/kallsyms | grep 'T startup_64'
ffffffff81000000 T startup_64
qemu
如果是使用 qemu 启动的内核,可以在 -append 选项中添加 nokaslr 来关闭 KASLR。
开启
物理机/虚拟机
修改/etc/default/grub文件,找到该文件中的GRUB_CMDLINE_LINUX配置项,去掉nokaslr。
qemu
如果是使用 qemu 启动的内核,可以在 -append 选项中添加 kaslr 来开启 KASLR。
绕过
与ASLR类似,KASLR也提高了攻击者对内核漏洞的利用门槛。例如,内核漏洞往往被用来进行提升权限或从容器中逃逸。攻击者在利用漏洞劫持控制流后,往往会去调用一个经典的内核函数组合以获取高权限:
commit_creds(prepare_creds());
系统启用KASLR后,攻击者在exploit中直接使用默认的内核符号地址就不再有效,攻击成本提高。然而,KASLR并不是完美的,后面提到的几种打印符号地址的方法即可能用来绕过KASLR。
同绕过ASLR一样,只要通过泄漏内核某个段的地址,就可以得到这个段内的所有地址。比如当我们泄漏了内核的代码段地址,就知道内核代码段的所有地址。
FGKASLR
2020 年,出现了更强大的 KASLR,称为FGKASLR (Function Granular KASLR)。,它默认被禁用。这是一项为每个 Linux 内核函数随机化地址的技术。即FGKASLR 在 KASLR 基地址随机化的基础上,在加载时刻,以函数粒度重新排布内核代码。
这项技术使得攻击者即使可以泄露Linux内核中某个函数的地址,也无法获取到基地址。但是,FGKASLR 并没有随机化数据部分,因此如果可以泄露数据的地址,就可以找到基地址。当然,不能从基地址中获取特定函数的地址,但可以用于特殊攻击向量。
目前,FGKASLR 只支持 x86_64 架构。其实现相对比较简单,主要在两个部分进行了修改。
- 编译阶段
- 加载阶段
开启
如果想要开启内核的 FGKASLR,需要开启 CONFIG_FG_KASLR=y 选项。
FGKASLR 也支持模块的随机化,尽管 FGKASLR 只支持 x86_64 架构下的内核,但是该特性可以支持其它架构下的模块。可以使用 CONFIG_MODULE_FG_KASLR=y 来开启这个特性。
关闭
通过在命令行使用 nokaslr 关闭 KASLR 也同时会关闭 FGKASLR。当然,我们可以单独使用 nofgkaslr 来关闭 FGKASLR。
关于FGKASLR更详细的内容可参考ctf-wiki-fgkaslr。
隔离
默认(User&Kernel)
用户态不可以直接访问内核态的数据、执行内核态的代码。
SMEP(User&Kernel)
SMEP(Supervisor Mode Execution Prevention,管理模式执行保护)。SMEP基于CPU提供的新特性,用来阻止不受信任应用程序以特权模式执行用户空间的代码,类似于NX。
出现的原因
起初,在内核态执行代码时,可以直接执行用户态的代码。那如果攻击者控制了内核中的执行流,就可以执行处于用户态的代码。由于用户态的代码是攻击者可控的,所以更容易实施攻击。为了防范这种攻击,研究者提出当位于内核态时,不能执行用户态的代码。在 Linux 内核中,这个防御措施的实现是与指令集架构相关的。
下面看看这种攻击场景:攻击者利用内核空间的漏洞控制了 RIP,同时攻击者在用户空间中准备了一段shellcode。如果SMEP被禁用,那么用户空间中的shellcode将会被执行。反之,如果SMEP开启了,执行shellcode时则会导致内核崩溃。
// mmap一段空间
char *shellcode = mmap( NULL , 0x1000 , PROT_READ|PROT_WRITE|PROT_EXECUTE,
MAP_ANONYMOUS | MAP_PRIVATE, -1 , 0 );
// 将shellcode拷贝到刚刚分配的那段内存空间中
memcpy (shellcode, SHELLCODE, sizeof (SHELLCODE));
// 控制rip指向shellcode
control_rip(shellcode); // RIP = shellcode
函数:
void *mmap(void *start,size_t length,int prot,int flags,int fd,off_t offsize);
功能(三种)
- 1、将一个普通文件映射到内存中,通常在需要对文件进行频繁读写时使用,这样用内存读写取代I/O读写,以获得较高的性能;
- 2、将特殊文件进行匿名内存映射,可以为关联进程提供共享内存空间;
- 3、为无关联的进程提供共享内存空间,一般也是将一个普通文件映射到内存中。
参数
start:指向欲映射的内存起始地址,通常设为 NULL,代表让系统自动选定地址,映射成功后返回该地址。
length:代表将文件中多大的部分映射到内存。
prot:映射区域的保护方式。可以为以下几种方式的组合:
- PROT_EXEC 映射区域可被执行
- PROT_READ 映射区域可被读取
- PROT_WRITE 映射区域可被写入
- PROT_NONE 映射区域不能存取
flags:影响映射区域的各种特性。在调用mmap()时必须要指定MAP_SHARED 或MAP_PRIVATE。
- MAP_FIXED 如果参数start所指的地址无法成功建立映射时,则放弃映射,不对地址做修正。通常不鼓励用此旗标。
- MAP_SHARED对映射区域的写入数据会复制回文件内,而且允许其他映射该文件的进程共享。
- MAP_PRIVATE 对映射区域的写入操作会产生一个映射文件的复制,即private的“写入时复制”(copy on write)对此区域作的任何修改都不会写回原来的文件内容。
- MAP_ANONYMOUS建立匿名映射。此时会忽略参数fd,不涉及文件,而且映射区域无法和其他进程共享。
- MAP_DENYWRITE只允许对映射区域的写入操作,其他对文件直接写入的操作将会被拒绝。
- MAP_LOCKED 将映射区域锁定住,这表示该区域不会被置换(swap)。
fd:要映射到内存中的文件描述符。如果使用匿名内存映射时,即flags中设置了MAP_ANONYMOUS,fd设为-1。有些系统不支持匿名内存映射,则可以使用fopen打开/dev/zero文件,然后对该文件进行映射,可以同样达到匿名内存映射的效果。
offset:文件映射的偏移量,通常设置为0,代表从文件最前方开始对应,offset必须是分页大小的整数倍。
返回值:若映射成功则返回映射区的内存起始地址,否则返回MAP_FAILED(-1),错误原因存于errno 中。
错误代码
- EBADF 参数fd 不是有效的文件描述词
- EACCES 存取权限有误。如果是MAP_PRIVATE 情况下文件必须可读,使用MAP_SHARED则要有PROT_WRITE以及该文件要能写入。
- EINVAL 参数start、length 或offset有一个不合法。
- EAGAIN 文件被锁住,或是有太多内存被锁住。
- ENOMEM 内存不足。
查看开启状态
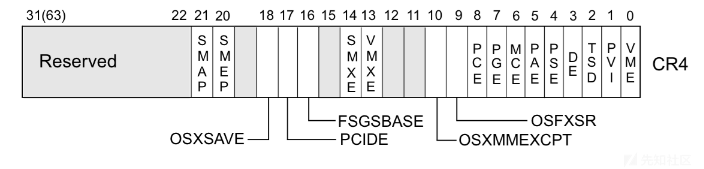
SMEP的开闭受CPU中CR4寄存器第20标识位的控制:
- 标识位设置1时,保护开启;
- 标识位设置0时,保护关闭。
下图为x86架构下的CR4寄存器。
可以从/proc/cpuinfo来知晓 SMEP是否开启,输出结果中flags包含了smep和smap,即说明SMEP/SMAP处于开启状态。下面有四个结果是因为这个虚拟机是4核的,且4个都开启了smep。
lzx@ubuntu:~/LKPWN/pawnyable$ cat /proc/cpuinfo | grep smep
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon nopl xtopology tsc_reliable nonstop_tsc cpuid pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single pti ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 avx2 smep bmi2 invpcid rdseed adx smap clflushopt xsaveopt xsavec xgetbv1 xsaves arat md_clear flush_l1d arch_capabilities
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon nopl xtopology tsc_reliable nonstop_tsc cpuid pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single pti ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 avx2 smep bmi2 invpcid rdseed adx smap clflushopt xsaveopt xsavec xgetbv1 xsaves arat md_clear flush_l1d arch_capabilities
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon nopl xtopology tsc_reliable nonstop_tsc cpuid pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single pti ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 avx2 smep bmi2 invpcid rdseed adx smap clflushopt xsaveopt xsavec xgetbv1 xsaves arat md_clear flush_l1d arch_capabilities
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon nopl xtopology tsc_reliable nonstop_tsc cpuid pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single pti ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 avx2 smep bmi2 invpcid rdseed adx smap clflushopt xsaveopt xsavec xgetbv1 xsaves arat md_clear flush_l1d arch_capabilities
开启
物理机/虚拟机
默认情况下,SMEP 保护是开启的。上面查看的/proc/cpuinfo是虚拟机的默认情况,可以看出时默认开启的。
qemu
我在LK01上测试的结果是,默认关闭smep。若要qemu 启动内核时启用SMEP,设置如下参数:
-cpu qemu64,+smep
修改LK01的run.sh,启用SMEP:
关闭
在 /etc/default/grub 的如下两行中添加 nosmep
GRUB_CMDLINE_LINUX_DEFAULT="quiet"
GRUB_CMDLINE_LINUX="initrd=/install/initrd.gz"
然后运行 update-grub 并且重启系统就可以关闭 smep。
如果是使用 qemu-system-x86_64启动的内核,默认是关闭 SMEP的。
绕过
把 CR4 寄存器中的第 20 位置为 0 后,我们就可以执行用户态的代码。一般而言,我们会使用 0x6f0 来设置 CR4,这样 SMAP 和 SMEP 都会被关闭。
内核中修改 cr4 的代码最终会调用到 native_write_cr4,当我们能够劫持控制流后,我们可以执行内核中的 gadget 来修改 CR4。从另外一个维度来看,内核中存在固定的修改 cr4 的代码,比如在 refresh_pce 函数、set_tsc_mode 等函数里都有。
具体的例子等后面遇到的时候再看吧。
SMAP(User&Kernel )
SMAP(Supervisor Mode Access Prevention,管理模式访问保护)建立在SMEP的基础上,可以视为SMEP的补充。用户空间不能读写内核空间的内存,这对于安全来说是理所当然的。而通过SMAP可阻止不受信任应用程序以特权模式读写用户空间的数据。
出现的原因
为什么要阻止从高权限内核空间往低权限用户空间中读取和写入数据呢?有两个原因:
- 阻止栈迁移:在劫持控制流后,攻击者可以通过栈迁移将栈迁移到用户态,然后进行 ROP,进一步达到提权的目的
- 防止内核编程错误导致的问题。
阻止Stack Pivot
在SMEP给出的例子中,即使可以控制RIP,也无法执行shellcode。但是别忘了,还有gadget这东西。比如:
mov esp, 0x12345678; ret;
无论移入 ESP 的值是什么,当调用此 ROP gadget时,RSP 都会更改为该值。若攻击者同时在0x12345678如此布局:
void *p = mmap( 0x12340000 , 0x10000 , ...);
unsigned long *chain = ( unsigned long *)(p + 0x5678 );
*chain++ = rop_pop_rdi;
*chain++ = 0 ;
*chain++ = ...;
.. .
control_rip(rop_mov_esp_12345678h);
/**
把0x12345678当作栈,布局如下:
0x12345678
0x12345680 rop_pop_rdi
0x12345688 0
......
**/
那么,即使启用了 SMEP,攻击者也可以通过获取 RIP 来执行上面的 ROP 链。
但是,如果启用了SMAP,则在用户空间(ROP 链)中映射的数据在内核空间中是不可见的,也就是没法把栈迁移到0x12345678。所以 stack pivot 时指令ret会导致内核崩溃。因此,SMEP 之外再启用 SMAP,可以缓解 ROP 的攻击。
防止内核编程错误
- 内核驱动
char buffer[0x10];
static long mydevice_ioctl(struct file *filp, unsigned int cmd, unsigned long arg) {
if (cmd == 0xdead) { // 若cmd为0xdead,则将用户空间数据拷贝到内核空间
memcpy(buffer, arg, 0x10);
} else if (cmd == 0xcafe) {// 若cmd为0xcafe,则将内核空间数据拷贝到用户空间
memcpy(arg, buffer, 0x10);
}
return
}
- 用户
int fd = open("/dev/mydevice", O_RDWR);
char src[0x10] = "Hello, World!";
char dst[0x10];
ioctl(fd, 0xdead, src); // 将 "Hello, World!" 拷贝到内核的buffer中
ioctl(fd, 0xcafe, dst); // 从内核的buffer拷贝数据到用户空间的dst
printf("%s\n", dst); // --> Hello, World!
memcpy的长度是0x10,好像没问题。但是如果SMAP 被禁用的时候,执行下面这样的代码:
ioctl(fd,0xdead,0xffffffffdeadbeef);
0xffffffffdeadbeef是用户空间的无效地址,但假设这是一个包含 Linux 内核中的秘密数据的地址。然后驱动执行memcpy,会将秘密数据拷贝到buffer,然后这个驱动就能读取到这个秘密数据了,这就导致了AAR。
memcpy(buffer, 0xffffffffdeadbeef, 0x10);
同样,若传入的cmd为0xcafe,也能修改那个秘密数据,导致AAW。
查看开启状态
SMAP的开闭受CPU中CR4寄存器第21标识位的控制:
- 标识位设置1时,保护开启;
- 标识位设置0时,保护关闭。
因此,一种绕过SMAP的手段是在高权限下通过修改CR4寄存器来关闭它。
同SMEP,可以从/proc/cpuinfo来知晓 SMAP是否开启:
# 查看smap是否开启
cat /proc/cpuinfo | grep smap
# 查看smep/smap是否开启
cat /proc/cpuinfo | grep -E "smep|smap"
开启
物理机/虚拟机
默认开启。
qemu
同SMEP,只不过将smep换成smap:
-cpu qemu64,+smap
关闭
在 /etc/default/grub 的如下两行中添加 nosmap
GRUB_CMDLINE_LINUX_DEFAULT="quiet"
GRUB_CMDLINE_LINUX="initrd=/install/initrd.gz"
然后运行 update-grub ,重启系统就可以关闭 smap。
绕过
设置 CR4 寄存器
把 CR4 寄存器中的第 21 位置为 0 后,我们就可以访问用户态的数据。一般而言,我们会使用 0x6f0 来设置 CR4,这样 SMAP 和 SMEP 都会被关闭。
内核中修改 cr4 的代码最终会调用到 native_write_cr4,当我们能够劫持控制流后,我们就可以执行内核中对应的 gadget 来修改 CR4。从另外一个维度来看,内核中存在固定的修改 cr4 的代码,比如在 refresh_pce 函数、set_tsc_mode 等函数里都有。
copy_from/to_user
在劫持控制流后,攻击者可以调用 copy_from_user 和 copy_to_user 来访问用户态的内存。这两个函数会临时清空禁止访问用户态内存的标志。
KPTI(User&Kernel)
KPTI(Kernel page-table isolation,内核页表隔离)也简称PTI,旧称KAISER。2018 年,在 Intel 等 CPU 上发现了一种名为Meltdown的侧信道攻击。该攻击可以用用户权限读取内核空间内存,并且可以绕过KASLR。
为了缓解改漏洞,提出了 KPTI 机制。该机制使得内核态空间的内存和用户态空间的内存的隔离进一步得到了增强。
- 内核态中的页表包括用户空间内存的页表和内核空间内存的页表。
- 用户态的页表只包括用户空间内存的页表以及必要的内核空间内存的页表,如用于处理系统调用、中断等信息的内存。
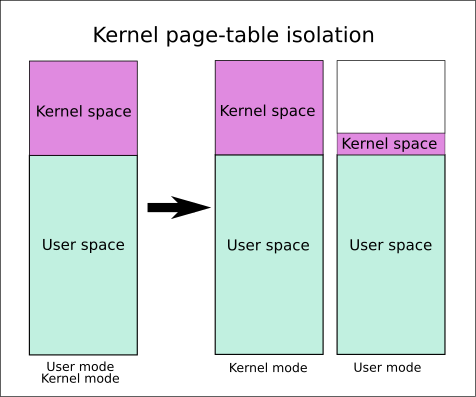
在 x86_64 的 PTI 机制中,内核态的用户空间内存映射部分被全部标记为不可执行。也就是说,之前不具有 SMEP 特性的硬件,如果开启了 KPTI 保护,也具有了类似于 SMEP 的特性。此外,SMAP 模拟也可以以类似的方式引入,只是现在还没有引入。因此,在目前开启了 KPTI 保护的内核中,如果没有开启 SMAP 保护,那么内核仍然可以访问用户态空间的内存,只是不能跳转到用户态空间执行 Shellcode。
查看开启状态
# 方法1:
/ # cat /proc/cpuinfo | grep pti
fpu_exception : yes
lzx@ubuntu:~/LKPWN/pawnyable$ cat /proc/cpuinfo | grep pti
fpu_exception : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon nopl xtopology tsc_reliable nonstop_tsc cpuid pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single pti ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 avx2 smep bmi2 invpcid rdseed adx smap clflushopt xsaveopt xsavec xgetbv1 xsaves arat md_clear flush_l1d arch_capabilities
fpu_exception : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon nopl xtopology tsc_reliable nonstop_tsc cpuid pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single pti ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 avx2 smep bmi2 invpcid rdseed adx smap clflushopt xsaveopt xsavec xgetbv1 xsaves arat md_clear flush_l1d arch_capabilities
fpu_exception : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon nopl xtopology tsc_reliable nonstop_tsc cpuid pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single pti ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 avx2 smep bmi2 invpcid rdseed adx smap clflushopt xsaveopt xsavec xgetbv1 xsaves arat md_clear flush_l1d arch_capabilities
fpu_exception : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon nopl xtopology tsc_reliable nonstop_tsc cpuid pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch cpuid_fault invpcid_single pti ssbd ibrs ibpb stibp fsgsbase tsc_adjust bmi1 avx2 smep bmi2 invpcid rdseed adx smap clflushopt xsaveopt xsavec xgetbv1 xsaves arat md_clear flush_l1d arch_capabilities
# 方法2:
/ # dmesg | grep 'page table' // 这个在LK01的qemu上没有回显
/ #
lzx@ubuntu:~/LKPWN/pawnyable$ dmesg | grep 'page table' // Host
[ 0.381988] Kernel/User page tables isolation: enabled
[ 4.059612] x86/mm: Checking user space page tables
qemu开启和关闭
如果是使用 qemu 启动的内核,在 -append 选项中添加 kpti=1 来开启 KPTI。
如果是使用 qemu 启动的内核,在 -append 选项中添加 nopti 来关闭 KPTI。
绕过
见ctf-wiki,后面遇到例子再细看。
CPU 漏洞缓解技术
前面提到KPTI是为了Meltdown漏洞而提出的。像Meltdown这些处理器级别的漏洞,虽然无法对已有硬件修复,但也会从软件层面用一些技术做缓解,路径 /sys/devices/system/cpu/vulnerabilities/ 下列出了所有针对 CPU 漏洞的缓解技术:
lzx@ubuntu:~/LKPWN/pawnyable$ ls /sys/devices/system/cpu/vulnerabilities/
itlb_multihit l1tf mds meltdown mmio_stale_data retbleed spec_store_bypass spectre_v1 spectre_v2 srbds tsx_async_abort
lzx@ubuntu:~/LKPWN/pawnyable$ cat /sys/devices/system/cpu/vulnerabilities/*
KVM: Vulnerable
Mitigation: PTE Inversion
Mitigation: Clear CPU buffers; SMT Host state unknown
Mitigation: PTI
Mitigation: Clear CPU buffers; SMT Host state unknown
Mitigation: IBRS
Mitigation: Speculative Store Bypass disabled via prctl and seccomp
Mitigation: usercopy/swapgs barriers and __user pointer sanitization
Mitigation: IBRS, IBPB: conditional, RSB filling, PBRSB-eIBRS: Not affected
Unknown: Dependent on hypervisor status
Not affected
每个文件对应一个漏洞,并且文件内容的字段有三种:
- Vulnerable:CPU 存在该漏洞,并且没有缓解技术
- Not affected:该漏洞不存在
- Mitigation:漏洞存在,并使用了缓解技术(对应的值就是具体技术)
比如 Meltdown 漏洞:
lzx@ubuntu:~/LKPWN/pawnyable$ cat /sys/devices/system/cpu/vulnerabilities/meltdown
Mitigation: PTI
表示使用了 PTI 缓解技术,实际上就是 KPTI,表示当前的系统已经启用了 KPTI。
堆块隔离(Inside Kernel)
如果在使用 kmem_cache_create 创建一个 cache 时,传递了 **SLAB_ACCOUNT** 标记,那么这个 cache 就会单独存在,不会与其它相同大小的 cache 合并。
Currently, if we want to account all objects of a particular kmem cache,
we have to pass __GFP_ACCOUNT to each kmem_cache_alloc call, which is
inconvenient. This patch introduces SLAB_ACCOUNT flag which if passed to
kmem_cache_create will force accounting for every allocation from this
cache even if __GFP_ACCOUNT is not passed.
This patch does not make any of the existing caches use this flag - it
will be done later in the series.
Note, a cache with SLAB_ACCOUNT cannot be merged with a cache w/o
SLAB_ACCOUNT, i.e. using this flag will probably reduce the number of
merged slabs even if kmem accounting is not used (only compiled in).
在早期,许多结构体(如 cred 结构体)对应的堆块并不单独存在,会和相同大小的堆块使用相同的 cache。在 Linux 4.5 版本引入了这个 flag 后,许多结构体就单独使用了自己的 cache。然而,根据上面的描述,这一特性似乎最初并不是为了安全性引入的。
访问控制
dmesg_restrict(信息泄露)
限制内核日志暴露,以防绕过KASLR。内核日志中可能会有一些地址信息或者敏感信息,所以需要对内核日志的访问进行限制。dmesg_restrict可用来决定是否限制非特权用户使用dmesg查看内核日志缓冲区中的消息。
- 值为0时,非特权用户对内核日志的查看将不受限制;
- 值为1时,只有具有
CAP_SYSLOG特权的用户才能查看内核日志。
查看开启状态
lzx@ubuntu:~/LKPWN/pawnyable$ cat /proc/sys/kernel/dmesg_restrict
0
开启
从上面查看开启状态可看出,dmesg_restrict默认是关闭的,非特权用户能够读取到内核日志:
lzx@ubuntu:~/LKPWN/pawnyable$ whoami
lzx
lzx@ubuntu:~/LKPWN/pawnyable$ grep CapEff /proc/self/status
CapEff: 0000000000000000
lzx@ubuntu:~/LKPWN/pawnyable$ dmesg | tail -n 3
[20382.441195] usb 2-2.1: reset full-speed USB device number 4 using uhci_hcd
[33640.723833] e1000: ens33 NIC Link is Down
[33644.753863] e1000: ens33 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: None
开启的方法就是将dmesg_restrict的值设置为1,然后非特权用户就不被允许读取内核日志了:
lzx@ubuntu:~/LKPWN/pawnyable$ sudo sh -c "echo 1 > /proc/sys/kernel/dmesg_restrict"
lzx@ubuntu:~/LKPWN/pawnyable$ dmesg | tail -n 3
dmesg: read kernel buffer failed: Operation not permitted
此时,只要具备了CAP_SYSLOG权限,依然能够读取内核日志:
lzx@ubuntu:~/LKPWN/pawnyable$ grep CapEff /proc/self/status
CapEff: 0000000000000000
lzx@ubuntu:~/LKPWN/pawnyable$ sudo sh -c "grep CapEff /proc/self/status"
[sudo] password for lzx:
CapEff: 0000003fffffffff
lzx@ubuntu:~/LKPWN/pawnyable$ capsh --decode=0000003fffffffff | grep "cap_syslog"
0x0000003fffffffff=cap_chown,cap_dac_override,cap_dac_read_search,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,cap_linux_immutable,cap_net_bind_service,cap_net_broadcast,cap_net_admin,cap_net_raw,cap_ipc_lock,cap_ipc_owner,cap_sys_module,cap_sys_rawio,cap_sys_chroot,cap_sys_ptrace,cap_sys_pacct,cap_sys_admin,cap_sys_boot,cap_sys_nice,cap_sys_resource,cap_sys_time,cap_sys_tty_config,cap_mknod,cap_lease,cap_audit_write,cap_audit_control,cap_setfcap,cap_mac_override,cap_mac_admin,cap_syslog,cap_wake_alarm,cap_block_suspend,cap_audit_read
lzx@ubuntu:~/LKPWN/pawnyable$ sudo dmesg | tail -n 3
[20382.441195] usb 2-2.1: reset full-speed USB device number 4 using uhci_hcd
[33640.723833] e1000: ens33 NIC Link is Down
[33644.753863] e1000: ens33 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: None
那么,设置dmesg_restrict限制有什么意义呢?dmesg_restrict的设置是为了避免非特权用户利用内核日志泄露的敏感信息绕过KASLR机制。我们知道,KASLR只是将内核基址在启动时做了随机化处理,但是内核中各符号之间的相对偏移是不受KASLR影响的。因此,只要能够获得内核基址或某符号地址,再结合偏移量,就能够计算出其他符号的准确地址,从而绕过KASLR。
例如,在以前的Linux环境下,我们可以直接从dmesg中获得内核基址:
dmesg | grep 'Freeing SMP'
能获得类似下面一样的输出:
Freeing SMP alternatives memory: 32K (ffffffff9e309000 - ffffffff9e311000)
其中,ffffffff9e309000就是内核基址了。然而,后来的一个内核补丁使得内核隐去了基址信息。补丁如下:
diff --git a/mm/page_alloc.c b/mm/page_alloc.c
index 2b3bf67..3f63973 100644
--- a/mm/page_alloc.c
+++ b/mm/page_alloc.c
@@ -6508,8 +6508,8 @@ unsigned long free_reserved_area(void *start, void *end, int poison, char *s)
}
if (pages && s)
- pr_info("Freeing %s memory: %ldK (%p - %p)\n",
- s, pages << (PAGE_SHIFT - 10), start, end);
+ pr_info("Freeing %s memory: %ldK\n",
+ s, pages << (PAGE_SHIFT - 10));
return pages;
}
因此,在我的测试环境中,执行上述命令也只能获得以下输出了:
lzx@ubuntu:~/LKPWN/pawnyable$ sudo dmesg | grep 'Freeing SMP'
[ 0.375721] Freeing SMP alternatives memory: 40K
可见,Linux内核的安全性是在不断提升的。但是,这并不说明dmesg不再能够泄露内核符号地址。在特定的场景下,攻击者可能通过其他手段让内核将某些符号地址主动输出到日志中,从而计算出所需的内核特定符号地址。
关闭
lzx@ubuntu:~/LKPWN/pawnyable$ sudo sh -c "echo 0 > /proc/sys/kernel/dmesg_restrict"
lzx@ubuntu:~/LKPWN/pawnyable$ dmesg | tail -n 3
[20382.441195] usb 2-2.1: reset full-speed USB device number 4 using uhci_hcd
[33640.723833] e1000: ens33 NIC Link is Down
[33644.753863] e1000: ens33 NIC Link is Up 1000 Mbps Full Duplex, Flow Control: None
KADR(kptr_restrict)(信息泄露)
KADR(Kernel Address Display Restriction,内核地址显示限制)限制内核符号地址暴露,以防绕过KASLR。此技术通过kptr_restrict的值来决定是否限制通过/proc或其他接口暴露内核中的符号地址(例如,通过/proc/kallsyms接口查看)。
- 值为0时,非特权用户能够查看内核符号地址(较新版本的内核还需要
perf_event_paranoid<=1); - 值为1时,只有具有
CAP_SYSLOG特权的用户才能查看内核符号地址; - 值为2时,即使是特权用户也无法查看内核符号地址。
当开启该保护后,攻击者就不能通过 /proc/kallsyms 来获取内核中某些敏感的地址了,如 commit_creds、prepare_kernel_cred。
查看开启状态
可以看到是默认开启的,查看的内核符号地址都是0
lzx@ubuntu:~/LKPWN/pawnyable$ cat /proc/sys/kernel/kptr_restrict
1
lzx@ubuntu:~/LKPWN/pawnyable$ cat /proc/kallsyms | tail -n 2
0000000000000000 t cleanup_module [pata_acpi]
0000000000000000 r __mod_pci__pacpi_pci_tbl_device_table [pata_acpi]
开启
lzx@ubuntu:~/LKPWN/pawnyable$ sudo sh -c "echo 1 > /proc/sys/kernel/kptr_restrict"
或者
lzx@ubuntu:~/LKPWN/pawnyable$ sudo sh -c "echo 2 > /proc/sys/kernel/kptr_restrict"
关闭
可以看到即使(5.4版本内核中)将kptr_restrict设置为0,非特权用户也无法获得内核符号地址。
lzx@ubuntu:~/LKPWN/pawnyable$ sudo sh -c "echo 0 > /proc/sys/kernel/kptr_restrict"
[sudo] password for lzx:
lzx@ubuntu:~/LKPWN/pawnyable$ cat /proc/sys/kernel/kptr_restrict
0
lzx@ubuntu:~/LKPWN/pawnyable$ cat /proc/kallsyms | tail -n 2
0000000000000000 t cleanup_module [pata_acpi]
0000000000000000 r __mod_pci__pacpi_pci_tbl_device_table [pata_acpi]
lzx@ubuntu:~/LKPWN/pawnyable$ uname -a
Linux ubuntu 5.4.0-135-generic #152~18.04.2-Ubuntu SMP Tue Nov 29 08:23:49 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux
原因很简单,还需要再设置一个值。先来看一下内核中与kptr_restrict相关的函数kallsyms_show_value
/*
* We show kallsyms information even to normal users if we've enabled
* kernel profiling and are explicitly not paranoid (so kptr_restrict
* is clear, and sysctl_perf_event_paranoid isn't set).
*
* Otherwise, require CAP_SYSLOG (assuming kptr_restrict isn't set to
* block even that).
*
* 返回1,表示可以显示内核符号地址;返回0,则表示不能显示
*/
int kallsyms_show_value(void)
{
switch (kptr_restrict) {
case 0: // 当kptr_restrict为0时,还需要kallsyms_for_perf()返回1才能return 1
if (kallsyms_for_perf())
return 1;
/* fallthrough */
case 1: // 当kptr_restrict为1时,还需要具备CAP_SYSLOG能力才能return 1
if (has_capability_noaudit(current, CAP_SYSLOG))
return 1;
/* fallthrough */
default:
return 0;
}
}
可以看到,kptr_restrict为0时,内核还要去判断kallsyms_for_perf函数是否返回真。这个函数就更简单了:
static inline int kallsyms_for_perf(void)
{
#ifdef CONFIG_PERF_EVENTS // 配置了CONFIG_PERF_EVENTS
extern int sysctl_perf_event_paranoid;
if (sysctl_perf_event_paranoid <= 1) // 且sysctl_perf_event_paranoid<=1
return 1; // 才会 return 1
#endif
return 0;
}
因此,对于上述版本的内核来说,只有在配置了CONFIG_PERF_EVENTS的情况下,设置kptr_restrict = 0,且设置perf_event_paranoid <= 1,非特权用户才能够获取到内核符号地址。安全性是有所提升的。
再试一下:
lzx@ubuntu:~/LKPWN/pawnyable$ sudo sh -c "echo 0 > /proc/sys/kernel/perf_event_paranoid"
lzx@ubuntu:~/LKPWN/pawnyable$ cat /proc/sys/kernel/perf_event_paranoid
0
lzx@ubuntu:~/LKPWN/pawnyable$ cat /proc/sys/kernel/kptr_restrict
0
lzx@ubuntu:~/LKPWN/pawnyable$ cat /proc/kallsyms | tail -n 2
ffffffffc004941d t cleanup_module [pata_acpi]
ffffffffc004a0c0 r __mod_pci__pacpi_pci_tbl_device_table [pata_acpi]
如上,我们在将perf_event_paranoid设置为0后,非特权用户就能够获得内核符号地址了。
那么,设置kptr_restrict限制有什么意义呢?同dmesg_restrict一样,这主要是为了防止内核符号地址被非特权用户恶意利用——例如,用来绕过KASLR。由于KASLR在系统启动时对内核基址做了随机化处理,攻击者在不进行暴力破解的情况下很难命中内核符号的正确地址,继而无法在Exploit中应用关键内核函数去实现权限提升等操作。如果作为非特权用户的攻击者能够借助/proc/kallsyms等方式获得有效的内核符号地址,KASLR就被绕过了。
例如,攻击者能够借此直接获得权限提升所需的关键内核函数地址:
lzx@ubuntu:~/LKPWN/pawnyable$ cat /proc/kallsyms | grep 'T commit_creds'
ffffffff9becd770 T commit_creds
lzx@ubuntu:~/LKPWN/pawnyable$ cat /proc/kallsyms | grep 'T prepare_kernel_cred'
ffffffff9becdbe0 T prepare_kernel_cred
__ro_after_init
Linux 内核中有很多数据都只会在 __init 阶段被初始化,而且之后不会被改变。使用 __ro_after_init 标记的内存,在 init 阶段结束后,不能够被再次修改。
可以使用 set_memory_rw(unsigned long addr, int numpages) 来修改对应页的权限。
mmap_min_addr
限制虚拟地址申请下界,以防NULL Pointer Dereference。
mmap_min_addr用来决定是否限制进程通过mmap能够申请到的内存的最小虚拟地址,或者说,限制进程申请的内存虚拟地址范围的下界。
Procfs等伪文件系统是Linux内核向用户态暴露接口的方式之一。mmap_min_addr在Linux下Procfs中对应的文件是/proc/sys/vm/mmap_min_addr。读取该文件即可查询当前系统的mmap_min_addr。
写该文件(需要满足权限要求)即可改变这个限制值。
首先查看一下当前的状态:
lzx@ubuntu:~/LKPWN/pawnyable$ whoami
lzx
lzx@ubuntu:~/LKPWN/pawnyable$ cat /proc/sys/vm/mmap_min_addr
65536
可以发现,进程能够申请的最小地址值为65536。在这种设定下,我们编写以下测试代码去申请零地址处的内存并尝试修改其内容:
#include <sys/mman.h>
#include <string.h>
#include <stdio.h>
int main(){
char hello = "hello, world";
mmap(0, 4096,PROT_READ | PROT_WRITE | PROT_EXEC, MAP_FIXED | MAP_PRIVATE | MAP_ANONYMOUS ,-1, 0);
printf("mmap succeeded!\n");
memcpy(0, hello, sizeof(hello));
return 0;
}
编译运行,出现了段错误:
lzx@ubuntu:~/LKPWN/pawnyable$ vim mmap_min_addr_test.c
lzx@ubuntu:~/LKPWN/pawnyable$ gcc mmap_min_addr_test.c -o mmap_min_addr_test
...(有一些告警信息)
lzx@ubuntu:~/LKPWN/pawnyable$ ./mmap_min_addr_test
mmap succeeded!
Segmentation fault (core dumped)
接着,我们修改mmap_min_addr为0,然后再次执行上述程序:
lzx@ubuntu:~/LKPWN/pawnyable$ sudo sh -c "echo 0 > /proc/sys/vm/mmap_min_addr"
lzx@ubuntu:~/LKPWN/pawnyable$ ./mmap_min_addr_test
mmap succeeded!
这次就执行成功了,说明mmap_min_addr的确发挥了作用。**然而mmap_min_addr有什么用处呢?**系统为什么要限制进程申请内存的地址范围下界呢?
简单来说,mmap_min_addr主要是为了限制空指针解引用(NULL Point Dereference)类型的攻击。为了理解这个问题,我们需要补充两个知识点:
- Linux系统将虚拟内存空间划分为用户空间和内核空间。以常见的32位系统为例,内核空间在用户空间之上,低地址的3G空间为用户空间;高地址的1G空间为内核空间。因此,空指针对应的零地址实际上是在用户空间范围内。
- 在大多数C语言实现中,未初始化指针的值为零(即零指针)。
综合起来,设想这样一种情形:攻击者在某程序中找到一个未初始化的函数指针,同时还能够向该程序的零地址处写入数据,那么攻击者就能够通过调用这个函数指针使该程序的控制流转向他写入的恶意指令。退一步讲,即使攻击者不能够控制该程序零地址处的内容,他也有可能通过空指针解引用触发段错误,从而导致程序崩溃,也就是一种拒绝服务攻击。
总结
- KASLR:
/etc/default/grub - SMEP/SMAP/KPTI:
/proc/cpuinfo - dmesg_restrict:
/proc/sys/kernel/dmesg_restrict - KADR(kptr_restrict):
/proc/sys/kernel/kptr_restrict - mmap_min_addr:
/proc/sys/vm/mmap_min_addr
SMEP/SMAP需要CPU的支持。
在版本较新的内核中,除了dmesg_restrict,上述漏洞缓解技术往往都处于启用状态。但是在老版本的内核或设备中,受功能限制或处于性能需求,一些漏洞缓解技术可能会被停用。