I woke up this morning and I thought to myself: “Why do we find it so difficult to learn a new skill?”
今天早上我醒来,我对自己说: “为什么我们发现学习一项新技能如此困难?”
I don’t think it’s just because of the hard work. I think that one of the reasons might be that we spend a lot of time and hard work acquiring knowledge by reading and watching and not enough time translating that knowledge into a skill by practicing it. Take swimming, for example. You can spend a lot of time reading hundreds of books about swimming, talk for hours with experienced swimmers and coaches, watch all the training videos available, and you still will sink like a rock the first time you jump in the pool.
我认为这不仅仅是因为辛苦的工作。我认为其中一个原因可能是我们花费了大量的时间和精力通过阅读和观察来获取知识,而没有足够的时间通过实践将知识转化为技能。以游泳为例。你可以花很多时间阅读数百本关于游泳的书籍,与经验丰富的游泳运动员和教练交谈几个小时,观看所有可用的训练视频,但是你仍然会在第一次跳进游泳池的时候像一块石头一样沉下去。
The bottom line is: it doesn’t matter how well you think you know the subject - you have to put that knowledge into practice to turn it into a skill. To help you with the practice part I put exercises into Part 1 and Part 2 of the series. And yes, you will see more exercises in today’s article and in future articles, I promise 😃
底线是: 无论你认为自己多么了解这门学科——你必须把这些知识转化为实践,把它变成一种技能。为了帮助您进行练习,我将练习放在本系列的第1部分和第2部分中。是的,你会在今天的文章和以后的文章中看到更多的练习,我保证:)
Okay, let’s get started with today’s material, shall we?
好了,让我们开始今天的内容,好吗?
So far, you’ve learned how to interpret arithmetic expressions that add or subtract two integers like “7 + 3” or “12 - 9”. Today I’m going to talk about how to parse (recognize) and interpret arithmetic expressions that have any number of plus or minus operators in it, for example “7 - 3 + 2 - 1”.
到目前为止,你已经学习了如何解释加减两个整数的算术表达式,比如“7 + 3”或“12-9”。今天我将讨论如何解析(识别)和解释包含任意数量正负运算符的算术表达式,例如“7-3 + 2-1”。
Graphically, the arithmetic expressions in this article can be represented with the following syntax diagram:
从图形上看,本文中的算术表达式可以用以下语法图表示:
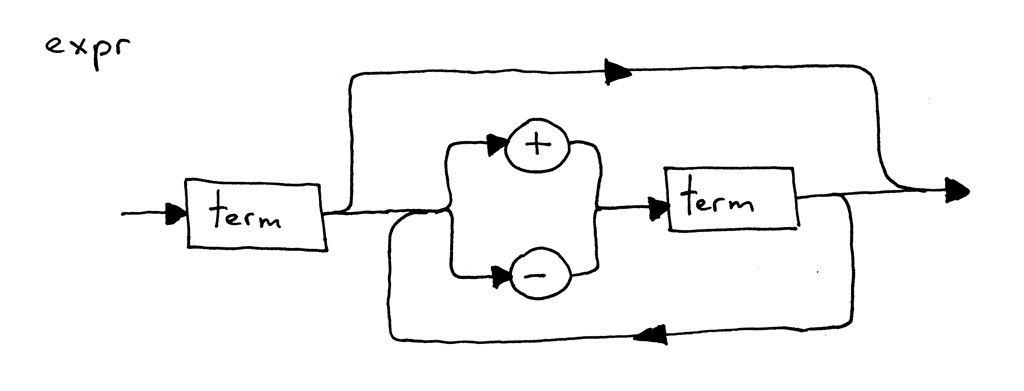
What is a syntax diagram? A syntax diagram is a graphical representation of a programming language’s syntax rules. Basically, a syntax diagram visually shows you which statements are allowed in your programming language and which are not.
什么是语法图?语法图是编程语言语法规则的图形化表示。基本上,语法图可视化地显示编程语言中哪些语句是允许的,哪些是不允许的。
Syntax diagrams are pretty easy to read: just follow the paths indicated by the arrows. Some paths indicate choices. And some paths indicate loops.
语法图很容易阅读: 只需沿着箭头所指示的路径走就可以了。有些路径表示选择。有些路径表示循环。
You can read the above syntax diagram as following: a term optionally followed by a plus or minus sign, followed by another term, which in turn is optionally followed by a plus or minus sign followed by another term and so on. You get the picture, literally. You might wonder what a “term” is. For the purpose of this article a “term” is just an integer.
你可以阅读上面的语法图: 一个term可选地后跟一个加号或减号,再后面跟着另一个term,这个term又可选地后跟一个加号或减号,后面又跟着另一个term等等。你明白了吧,真的。你可能想知道“term”是什么。对于本文来说,“ term”只是一个整数。
Syntax diagrams serve two main purposes:
语法图有两个主要用途:
- They graphically represent the specification (grammar) of a programming language.
- 它们以图形方式表示编程语言的规范(语法)
- They can be used to help you write your parser - you can map a diagram to code by following simple rules.
- 它们可以用来帮助你编写解析器——你可以通过遵循简单的规则将图表映射到代码
You’ve learned that the process of recognizing a phrase in the stream of tokens is called parsing. And the part of an interpreter or compiler that performs that job is called a parser. Parsing is also called syntax analysis, and the parser is also aptly called, you guessed it right, a syntax analyzer.
你已经了解到,识别token流中的phrase的过程称为解析。解释器或编译器中执行这项工作的部分称为解析器。解析也称为语法分析,解析器也恰如其分地称为语法分析器(你猜对了)。
According to the syntax diagram above, all of the following arithmetic expressions are valid:
根据上面的语法图,下面所有的算术表达式都是有效的:
- 3
- 3 + 4 3 + 4
- 7 - 3 + 2 - 1 7-3 + 2-1
Because syntax rules for arithmetic expressions in different programming languages are very similar we can use a Python shell to “test” our syntax diagram. Launch your Python shell and see for yourself:
因为不同编程语言中算术表达式的语法规则非常相似,所以我们可以使用 Python shell 来“测试”我们的语法图。启动你的 Python shell,自己看看:
>>> 3
3
>>> 3 + 4
7
>>> 7 - 3 + 2 - 1
5
No surprises here.
这里没有惊喜。
The expression “3 + ” is not a valid arithmetic expression though because according to the syntax diagram the plus sign must be followed by a term (integer), otherwise it’s a syntax error. Again, try it with a Python shell and see for yourself:
表达式“3 +”不是一个有效的算术表达式,因为根据语法图表,加号后面必须跟着一个term(整数) ,否则它是一个语法错误。再次,用 Python shell 尝试一下,你自己看看:
>>> 3 +
File "<stdin>", line 1
3 +
^
SyntaxError: invalid syntax
It’s great to be able to use a Python shell to do some testing but let’s map the above syntax diagram to code and use our own interpreter for testing, all right?
能够使用 Python shell 进行一些测试是很棒的,但是让我们将上面的语法图映射到代码中,并使用我们自己的解释器进行测试,好吗?
You know from the previous articles (Part 1 and Part 2) that the expr method is where both our parser and interpreter live. Again, the parser just recognizes the structure making sure that it corresponds to some specifications and the interpreter actually evaluates the expression once the parser has successfully recognized (parsed) it.
从前面的文章(第1部分和第2部分)中可以知道,expr 方法是我们的解析器和解释器所在的地方。同样,解析器只是识别结构,确保它对应于某些规范,并且解释器实际上在解析器成功识别(解析)表达式之后对其进行计算。
The following code snippet shows the parser code corresponding to the diagram. The rectangular box from the syntax diagram (term) becomes a term method that parses an integer and the expr method just follows the syntax diagram flow:
下面的代码片段显示了与图对应的解析器代码。语法图(term)中的矩形框变成了解析整数的 term 方法,expr 方法只遵循语法图流程:
def term(self):
self.eat(INTEGER)
def expr(self):
# set current token to the first token taken from the input
self.current_token = self.get_next_token()
self.term()
while self.current_token.type in (PLUS, MINUS):
token = self.current_token
if token.type == PLUS:
self.eat(PLUS)
self.term()
elif token.type == MINUS:
self.eat(MINUS)
self.term()
You can see that expr first calls the term method. Then the expr method has a while loop which can execute zero or more times. And inside the loop the parser makes a choice based on the token (whether it’s a plus or minus sign). Spend some time proving to yourself that the code above does indeed follow the syntax diagram flow for arithmetic expressions.
可以看到 expr 首先调用 term 方法。然后 expr 方法有一个 while 循环,可以执行零次或更多次。在循环中,解析器根据token(是加号还是减号)做出选择。花些时间证明上面的代码确实遵循了算术表达式的语法图流程。
The parser itself does not interpret anything though: if it recognizes an expression it’s silent and if it doesn’t, it throws out a syntax error. Let’s modify the expr method and add the interpreter code:
但是解析器本身并不解释任何东西:如果它识别出一个表达式,那么它就是静默的,如果它没有,那么它就会抛出一个语法错误。让我们修改 expr 方法并添加解释器代码:
def term(self):
"""Return an INTEGER token value"""
token = self.current_token # 获取当前token
self.eat(INTEGER) # 如果当前token是整数
return token.value # 那么返回token的值
def expr(self):
"""Parser / Interpreter """
# set current token to the first token taken from the input
self.current_token = self.get_next_token()
result = self.term()
while self.current_token.type in (PLUS, MINUS):
token = self.current_token
if token.type == PLUS:
self.eat(PLUS)
result = result + self.term()
elif token.type == MINUS:
self.eat(MINUS)
result = result - self.term()
return result
Because the interpreter needs to evaluate an expression the term method was modified to return an integer value and the expr method was modified to perform addition and subtraction at the appropriate places and return the result of interpretation. Even though the code is pretty straightforward I recommend spending some time studying it.
由于解释器需要计算一个表达式,所以对 term 方法进行了修改,以返回一个整数值,而对 expr 方法进行了修改,以便在适当的位置执行加减操作,并返回解释结果。尽管代码非常简单,我还是建议你花点时间研究一下。
Le’s get moving and see the complete code of the interpreter now, okay?
我们现在开始,看看解释器的完整代码,好吗?
Here is the source code for your new version of the calculator that can handle valid arithmetic expressions containing integers and any number of addition and subtraction operators:
下面是新版计算器的源代码,它可以处理包含整数和任意数量的加减运算符的有效算术表达式:
# Token types
#
# EOF (end-of-file) token is used to indicate that
# there is no more input left for lexical analysis
INTEGER, PLUS, MINUS, EOF = 'INTEGER', 'PLUS', 'MINUS', 'EOF'
class Token(object):
def __init__(self, type, value):
# token type: INTEGER, PLUS, MINUS, or EOF
self.type = type
# token value: non-negative integer value, '+', '-', or None
self.value = value
def __str__(self):
"""String representation of the class instance.
Examples:
Token(INTEGER, 3)
Token(PLUS, '+')
"""
return 'Token({type}, {value})'.format(
type=self.type,
value=repr(self.value)
)
def __repr__(self):
return self.__str__()
class Interpreter(object):
def __init__(self, text):
# client string input, e.g. "3 + 5", "12 - 5 + 3", etc
self.text = text
# self.pos is an index into self.text
self.pos = 0
# current token instance
self.current_token = None
self.current_char = self.text[self.pos]
##########################################################
# Lexer code 词法分析器代码 #
##########################################################
def error(self):
raise Exception('Invalid syntax')
def advance(self):
"""Advance the `pos` pointer and set the `current_char` variable."""
self.pos += 1
if self.pos > len(self.text) - 1:
self.current_char = None # Indicates end of input
else:
self.current_char = self.text[self.pos]
def skip_whitespace(self):
while self.current_char is not None and self.current_char.isspace():
self.advance()
def integer(self):
"""Return a (multidigit) integer consumed from the input."""
result = ''
while self.current_char is not None and self.current_char.isdigit():
result += self.current_char
self.advance()
return int(result)
def get_next_token(self):
"""Lexical analyzer (also known as scanner or tokenizer)
This method is responsible for breaking a sentence
apart into tokens. One token at a time.
"""
while self.current_char is not None:
if self.current_char.isspace():
self.skip_whitespace()
continue
if self.current_char.isdigit():
return Token(INTEGER, self.integer())
if self.current_char == '+':
self.advance()
return Token(PLUS, '+')
if self.current_char == '-':
self.advance()
return Token(MINUS, '-')
self.error()
return Token(EOF, None)
##########################################################
# Parser / Interpreter code 解析器/解释器代码 #
##########################################################
def eat(self, token_type):
# compare the current token type with the passed token 比较当前token的type和传入的token的type是否一样
# type and if they match then "eat" the current token
# and assign the next token to the self.current_token, 如果一样,则将self.get_next_token返回的值赋值给self.current_token
# otherwise raise an exception.
if self.current_token.type == token_type:
self.current_token = self.get_next_token()
else:
self.error()
def term(self):
"""Return an INTEGER token value.
返回一个 INTERGER token的值
"""
token = self.current_token
self.eat(INTEGER)
return token.value
def expr(self):
"""Arithmetic expression parser / interpreter.
算术表达式解析器/解释器
"""
# set current token to the first token taken from the input
self.current_token = self.get_next_token() # 从输入获取第一个token
result = self.term() # 得到第一个token的值,并将下一个token给self.current_token
while self.current_token.type in (PLUS, MINUS): # 通过判断当前token的值是否是加法或减法
token = self.current_token # 操作符
if token.type == PLUS: # 根据操作符的类型,做相应的操作
self.eat(PLUS) # 吃掉+操作符,并将下一个token给self.current_token
result = result + self.term() # self.term()返回“第二个”操作数的值,并将下一个token赋值给self.current_token,用于循环的进行,这是循环的关键!!!
elif token.type == MINUS:
self.eat(MINUS)
result = result - self.term()
return result
def main():
while True:
try:
text = input('calc> ')
except EOFError:
break
if not text:
continue
interpreter = Interpreter(text)
result = interpreter.expr()
print(result)
if __name__ == '__main__':
main()
Save the above code into the calc3.py file or download it directly from GitHub. Try it out. See for yourself that it can handle arithmetic expressions that you can derive from the syntax diagram I showed you earlier.
将上面的代码保存到 calc3.py 文件中,或者直接从 GitHub 下载。尝试一下。你自己看看,它可以处理您可以从我前面给你展示的语法图中派生出来的算术表达式。
Here is a sample session that I ran on my laptop:
下面是我在笔记本电脑上运行的一个示例会话:
$ python calc3.py
calc> 3
3
calc> 7 - 4
3
calc> 10 + 5
15
calc> 7 - 3 + 2 - 1
5
calc> 10 + 1 + 2 - 3 + 4 + 6 - 15
5
calc> 3 +
Traceback (most recent call last):
File "calc3.py", line 147, in <module>
main()
File "calc3.py", line 142, in main
result = interpreter.expr()
File "calc3.py", line 123, in expr
result = result + self.term()
File "calc3.py", line 110, in term
self.eat(INTEGER)
File "calc3.py", line 105, in eat
self.error()
File "calc3.py", line 45, in error
raise Exception('Invalid syntax')
Exception: Invalid syntax
Remember those exercises I mentioned at the beginning of the article: here they are, as promised 😃
还记得我在文章开头提到的大量练习吗
- Draw a syntax diagram for arithmetic expressions that contain only multiplication and division, for example “7 * 4 / 2 * 3”. Seriously, just grab a pen or a pencil and try to draw one.
- 为只包含乘法和除法的算术表达式绘制语法图,例如“7 * 4/2 * 3”。说真的,抓起一支钢笔或铅笔试着画一个
- Modify the source code of the calculator to interpret arithmetic expressions that contain only multiplication and division, for example “7 * 4 / 2 * 3”.
- 修改计算器的源代码以解释只包含乘法和除法的算术表达式,例如“7 * 4/2 * 3”
- Write an interpreter that handles arithmetic expressions like “7 - 3 + 2 - 1” from scratch. Use any programming language you’re comfortable with and write it off the top of your head without looking at the examples. When you do that, think about components involved: a lexer that takes an input and converts it into a stream of tokens, a parser that feeds off the stream of the tokens provided by the lexer and tries to recognize a structure in that stream, and an interpreter that generates results after the parser has successfully parsed (recognized) a valid arithmetic expression. String those pieces together. Spend some time translating the knowledge you’ve acquired into a working interpreter for arithmetic expressions.
- 编写一个解释器,从头开始处理算术表达式,如“7 - 3 + 2 - 1”。使用任何你熟悉的编程语言,不用看例子就直接写下来。当你这样做时,考虑一下相关的组件:一个获取输入并将其转换为一连串的token的词法分析器,一个从词法分析器获取token流,并尝试识别流结构的解析器,和一个在解析器成功解析一个算术表达式后生成结果的解释器。把这些碎片串在一起,花些时间把你学到的知识转换成一个算术表达式解释器。
我的答案:
# Token types
#
# EOF (end-of-file) token is used to indicate that
# there is no more input left for lexical analysis
INTEGER, PLUS, MINUS, MUL, DIV, EOF = 'INTEGER', 'PLUS', 'MINUS', 'MUL', 'DIV', 'EOF'
class Token(object):
def __init__(self, type, value):
# token type: INTEGER, PLUS, MINUS, or EOF
self.type = type
# token value: non-negative integer value, '+', '-', or None
self.value = value
def __str__(self):
"""String representation of the class instance.
Examples:
Token(INTEGER, 3)
Token(PLUS, '+')
"""
return 'Token({type}, {value})'.format(
type=self.type,
value=repr(self.value)
)
def __repr__(self):
return self.__str__()
class Interpreter(object):
def __init__(self, text):
# client string input, e.g. "3 + 5", "12 - 5 + 3", etc
self.text = text
# self.pos is an index into self.text
self.pos = 0
# current token instance
self.current_token = None
self.current_char = self.text[self.pos]
##########################################################
# Lexer code 词法分析器代码 #
##########################################################
def error(self):
raise Exception('Invalid syntax')
def advance(self):
"""Advance the `pos` pointer and set the `current_char` variable."""
self.pos += 1
if self.pos > len(self.text) - 1:
self.current_char = None # Indicates end of input
else:
self.current_char = self.text[self.pos]
def skip_whitespace(self):
while self.current_char is not None and self.current_char.isspace():
self.advance()
def integer(self):
"""Return a (multidigit) integer consumed from the input."""
result = ''
while self.current_char is not None and self.current_char.isdigit():
result += self.current_char
self.advance()
return int(result)
def get_next_token(self):
"""Lexical analyzer (also known as scanner or tokenizer)
This method is responsible for breaking a sentence
apart into tokens. One token at a time.
"""
while self.current_char is not None:
if self.current_char.isspace():
self.skip_whitespace()
continue
if self.current_char.isdigit():
return Token(INTEGER, self.integer())
if self.current_char == '+':
self.advance()
return Token(PLUS, '+')
if self.current_char == '-':
self.advance()
return Token(MINUS, '-')
if self.current_char == '*':
self.advance()
return Token(MUL, '*')
if self.current_char == '/':
self.advance()
return Token(DIV, '/')
self.error()
return Token(EOF, None)
##########################################################
# Parser / Interpreter code 解析器/解释器代码 #
##########################################################
def eat(self, token_type):
# compare the current token type with the passed token 比较当前token的type和传入的token的type是否一样
# type and if they match then "eat" the current token
# and assign the next token to the self.current_token, 如果一样,则将self.get_next_token返回的值赋值给self.current_token
# otherwise raise an exception.
if self.current_token.type == token_type:
self.current_token = self.get_next_token()
else:
self.error()
def term(self):
"""Return an INTEGER token value.
返回一个 INTERGER token的值
"""
token = self.current_token
self.eat(INTEGER)
return token.value
def expr(self):
"""Arithmetic expression parser / interpreter.
算术表达式解析器/解释器
"""
# set current token to the first token taken from the input
self.current_token = self.get_next_token() # 从输入获取第一个token
result = self.term() # 得到第一个token的值,并将下一个token给self.current_token
while self.current_token.type in (PLUS, MINUS, MUL, DIV): # 通过判断当前token的值是否是加法或减法
token = self.current_token # 操作符
if token.type == PLUS: # 根据操作符的类型,做相应的操作
self.eat(PLUS) # 吃掉+操作符,并将下一个token给self.current_token
result = result + self.term() # self.term()返回“第二个”操作数的值,并将下一个token赋值给self.current_token,用于循环的进行,这是循环的关键!!!
elif token.type == MINUS:
self.eat(MINUS)
result = result - self.term()
elif token.type == MUL:
self.eat(MUL)
result = result * self.term()
elif token.type == DIV:
self.eat(DIV)
right = self.term()
if right == 0:
self.error()
else:
result = result / right
return result
def main():
while True:
try:
text = input('calc> ')
except EOFError:
break
if not text:
continue
interpreter = Interpreter(text)
result = interpreter.expr()
print(result)
if __name__ == '__main__':
main()
Check your understanding.
检查你的理解。
- What is a syntax diagram? 什么是语法图?
编程语言语法规则的图形化表示。语法图可视化地显示编程语言中哪些语句是允许的,哪些是不允许的
- What is syntax analysis? 什么是语法分析?
即解析。从token流中识别结构,得到phrase的过程
- What is a syntax analyzer? 什么是语法分析器?
即解析器。解释器/编译器执行解析的那部分。
Hey, look! You read all the way to the end. Thanks for hanging out here today and don’t forget to do the exercises. 😃 I’ll be back next time with a new article - stay tuned.
嘿,看!你从头读到尾。谢谢你今天来这里,别忘了做练习。(收集整理下次我会带来一篇新文章,敬请期待。
Here is a list of books I recommend that will help you in your study of interpreters and compilers:
以下是我推荐的一些书籍,它们可以帮助你学习解释器和编译器:
- Language Implementation Patterns: Create Your Own Domain-Specific and General Programming Languages (Pragmatic Programmers)
语言实现模式: 创建您自己的特定领域和通用编程语言(实用程序员) - Writing Compilers and Interpreters: A Software Engineering Approach
编写编译器和解释器: 一种软件工程方法 - Modern Compiler Implementation in Java
现代编译器在 Java 中的实现 - Modern Compiler Design
现代编译器设计 - Compilers: Principles, Techniques, and Tools (2nd Edition)
编译器: 原理、技术和工具(第二版)
All articles in this series:
本系列的所有文章:
- Let's Build A Simple Interpreter. Part 1. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 2. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 3. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 4. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 5. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 6. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 7: Abstract Syntax Trees 让我们构建一个简单的解释器。第7部分: 抽象语法树
- Let's Build A Simple Interpreter. Part 8. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 9. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 10. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 11. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 12.
- Let's Build A Simple Interpreter. Part 13: Semantic Analysis
- Let's Build A Simple Interpreter. Part 14: Nested Scopes and a Source-to-Source Compiler
- Let's Build A Simple Interpreter. Part 15.
- Let's Build A Simple Interpreter. Part 16: Recognizing Procedure Calls
- Let's Build A Simple Interpreter. Part 17: Call Stack and Activation Records
- Let's Build A Simple Interpreter. Part 18: Executing Procedure Calls
- Let's Build A Simple Interpreter. Part 19: Nested Procedure Calls