“If you don’t know how compilers work, then you don’t know how computers work. If you’re not 100% sure whether you know how compilers work, then you don’t know how they work.” — Steve Yegge
“如果你不知道编译器是如何工作的,那么你就不知道计算机是如何工作的。如果你不能100% 确定你是否知道编译器是如何工作的,那么你就是不知道它们是如何工作的。”ー Steve Yegge
There you have it. Think about it. It doesn’t really matter whether you’re a newbie or a seasoned software developer: if you don’t know how compilers and interpreters work, then you don’t know how computers work. It’s that simple.
这就对了。想想吧。不管你是新手还是经验丰富的软件开发人员,这都不重要: 如果你不知道编译器和解释器是如何工作的,那么你就不知道计算机是如何工作的。就是这么简单。
So, do you know how compilers and interpreters work? And I mean, are you 100% sure that you know how they work? If you don’t.
那么,你知道编译器和解释器是如何工作的吗?我的意思是,你100% 确定你知道它们是如何工作的吗?如果你不知道。

Or if you don’t and you’re really agitated about it.
或者如果你不知道并且你真的对此感到焦虑。

Do not worry. If you stick around and work through the series and build an interpreter and a compiler with me you will know how they work in the end. And you will become a confident happy camper too. At least I hope so.
别担心。如果你坚持读完这个系列,和我一起构建一个解释器和一个编译器,你最终就会知道它们是如何工作的。你也会成为一个自信快乐的露营者。至少我希望如此。(露营者??是一个我不知道的英语典故吗?)

Why would you study interpreters and compilers? I will give you three reasons.
为什么要学习解释器和编译器? 我给你三个理由。
- To write an interpreter or a compiler you have to have a lot of technical skills that you need to use together. Writing an interpreter or a compiler will help you improve those skills and become a better software developer. As well, the skills you will learn are useful in writing any software, not just interpreters or compilers.
要编写一个解释器或编译器,你必须具备需要一起使用的许多技能。编写一个解释器或编译器将帮助你提高这些技能,并成为一个更好的软件开发人员。同时,你学到的技能对编写任何软件都是有用的,而不仅仅是解释器或编译器。 - You really want to know how computers work. Often interpreters and compilers look like magic. And you shouldn’t be comfortable with that magic. You want to demystify the process of building an interpreter and a compiler, understand how they work, and get in control of things.
你真的很想知道电脑是怎么工作的。通常解释器和编译器看起来像魔法,你不应该安于使用这种魔法。你希望了解构建解释器和编译器的过程,了解它们是如何工作的。 - You want to create your own programming language or domain specific language. If you create one, you will also need to create either an interpreter or a compiler for it. Recently, there has been a resurgence of interest in new programming languages. And you can see a new programming language pop up almost every day: Elixir, Go, Rust just to name a few.
你希望创建自己的编程语言或针对某个领域特定的语言。如果你创建了一个,你也需要为它创建一个解释器或者一个编译器。最近,人们对新编程语言的兴趣重新燃起。你可以看到几乎每天都有一种新的编程语言出现: Elixir、Go和Rust 等等。
Okay, but what are interpreters and compilers?
好的,但是什么是解释器和编译器呢?
The goal of an interpreter or a compiler is to translate a source program in some high-level language into some other form. Pretty vague, isn’t it? Just bear with me, later in the series you will learn exactly what the source program is translated into.
解释器或编译器的目标是将某种高级语言中的源程序翻译成另一种形式。很模糊是吗?请耐心等待,在本系列的后面,你将了解源程序到底被翻译成了什么。
At this point you may also wonder what the difference is between an interpreter and a compiler. For the purpose of this series, let’s agree that if a translator translates a source program into machine language, it is a compiler. If a translator processes and executes the source program without translating it into machine language first, it is an interpreter. Visually it looks something like this:
在这一点上,你可能还想知道解释器和编译器之间的区别。对于本系列文章,我们一致认为,如果翻译器将源程序翻译成机器语言,那么它就是编译器。如果翻译器在没有先将源程序翻译成机器语言的情况下处理并执行源程序,那么它就是一个解释器。从视觉上看是这样的:
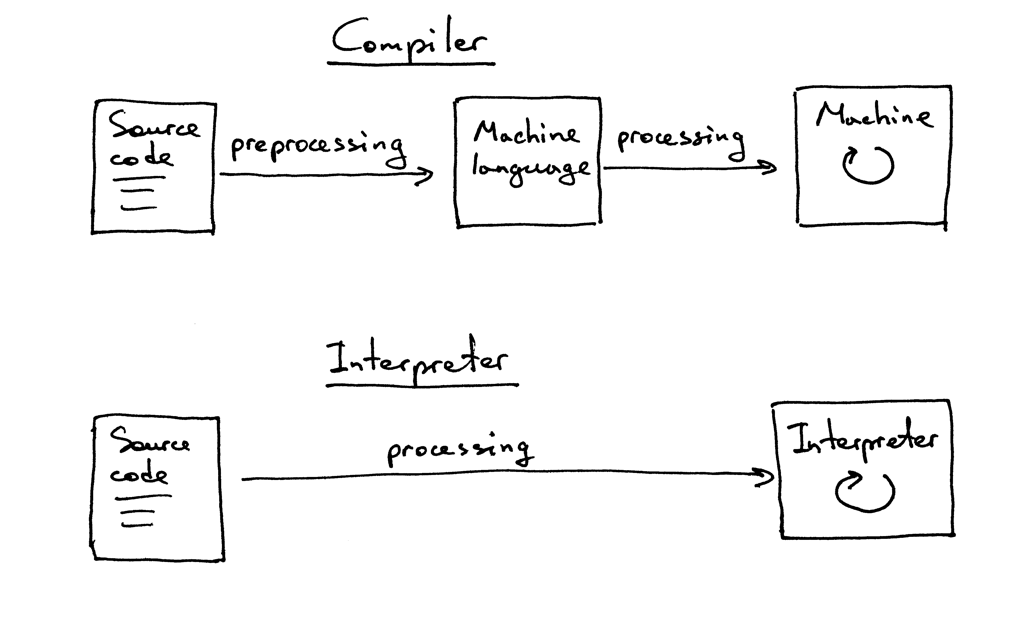
I hope that by now you’re convinced that you really want to study and build an interpreter and a compiler. What can you expect from this series on interpreters?
我希望到目前为止,你已经确信您真的想学习并构建一个解释器和编译器。你能从这个关于解释器的系列文章中期待些什么呢?
Here is the deal. You and I are going to create a simple interpreter for a large subset of Pascal language. At the end of this series you will have a working Pascal interpreter and a source-level debugger like Python’s pdb.
是这样的,我们将为 Pascal 语言的一个大子集创建一个简单的解释器。在本系列的最后,你将拥有一个可用的 Pascal 解释器和一个源代码级别的调试器,如 Python 的 pdb。
You might ask, why Pascal? For one thing, it’s not a made-up language that I came up with just for this series: it’s a real programming language that has many important language constructs. And some old, but useful, CS books use Pascal programming language in their examples (I understand that that’s not a particularly compelling reason to choose a language to build an interpreter for, but I thought it would be nice for a change to learn a non-mainstream language 😃
你可能会问,为什么是Pascal?首先,它不是我为这个系列编写的虚构语言: 它是一种真正的编程语言,具有许多重要的语言结构。一些古老但有用的 CS 书籍在他们的例子中使用 Pascal 编程语言(我知道这并不是一个特别有说服力的理由去选择一种语言来建立一个解释器,但是我认为学习一种非主流语言是一个很好的改变:)
Here is an example of a factorial function in Pascal that you will be able to interpret with your own interpreter and debug with the interactive source-level debugger that you will create along the way:
这里有一个 Pascal 语言的阶乘函数的例子,你可以用你自己的解释器来解释它,并且可以用你一路创建的交互式源代码级调试器来进行调试:
The implementation language of the Pascal interpreter will be Python, but you can use any language you want because the ideas presented don’t depend on any particular implementation language. Okay, let’s get down to business. Ready, set, go!
Pascal 解释器的实现语言是 Python,但是你可以使用任何你想使用的语言,因为所提出的想法不依赖于任何特定的实现语言。好了,我们开始谈正事吧。准备,预备,开始!
You will start your first foray into interpreters and compilers by writing a simple interpreter of arithmetic expressions, also known as a calculator. Today the goal is pretty minimalistic: to make your calculator handle the addition of two single digit integers like 3+5. Here is the source code for your calculator, sorry, interpreter:
您将通过编写一个简单的算术表达式解释器(也称为计算器)来开始对解释器和编译器进行第一次尝试。今天的目标是非常简单的:让你的计算器处理两个整数数字的加法,比如3 + 5。下面是你的计算器/解释器的源代码:
Save the above code into calc1.py file or download it directly from GitHub. Before you start digging deeper into the code, run the calculator on the command line and see it in action. Play with it! Here is a sample session on my laptop (if you want to run the calculator under Python3 you will need to replace raw_input with input):
将上面的代码保存到 calc1.py 文件中,或者直接从 GitHub 下载。在开始深入研究代码之前,请在命令行上运行该计算器并查看其实际操作。玩吧!下面是我笔记本电脑上的一个示例:
For your simple calculator to work properly without throwing an exception, your input needs to follow certain rules:
为了让你的简单计算器正常工作而不引发异常,你的输入需要遵循一定的规则:
- Only single digit integers are allowed in the input 输入中只允许个位整数
- The only arithmetic operation supported at the moment is addition 目前唯一支持的算术运算是加法
- No whitespace characters are allowed anywhere in the input 输入中的任何地方都不允许有空格字符
Those restrictions are necessary to make the calculator simple. Don’t worry, you’ll make it pretty complex pretty soon.
这些限制对于简化计算器是必要的。不必担心,很快你就会把它变得相当复杂。
Okay, now let’s dive in and see how your interpreter works and how it evaluates arithmetic expressions.
好,现在让我们深入了解解释器是如何工作的,以及它如何计算算术表达式的。
When you enter an expression 3+5 on the command line your interpreter gets a string “3+5”. In order for the interpreter to actually understand what to do with that string it first needs to break the input “3+5” into components called tokens. A token is an object that has a type and a value. For example, for the string “3” the type of the token will be INTEGER and the corresponding value will be integer 3.
当你在命令行中输入表达式3 + 5时,你的解释器将得到一个字符串“3 + 5”。为了让解释器真正理解如何处理这个字符串,它首先需要将输入“3 + 5”分解为称为token的组件。token是具有类型(type)和值(value)的对象。例如,对于字符串“3”,token的类型为 INTEGER,相应的值为整数 3。
The process of breaking the input string into tokens is called lexical analysis. So, the first step your interpreter needs to do is read the input of characters and convert it into a stream of tokens. The part of the interpreter that does it is called a lexical analyzer, or lexer for short. You might also encounter other names for the same component, like scanner or tokenizer. They all mean the same: the part of your interpreter or compiler that turns the input of characters into a stream of tokens.
将输入字符串分解成token的过程称为词法分析。因此,你的解释器需要完成的第一步是读取字符输入并将其转换为token流。解释器中做这项工作的部分称为词法分析器,简称lexer。你还可能会遇到lexer的其他名称,如扫描器(scanner)或标记器(tokenizer)。它们的意思都是一样的: 解释器或编译器中将字符输入转换为token流的部分。
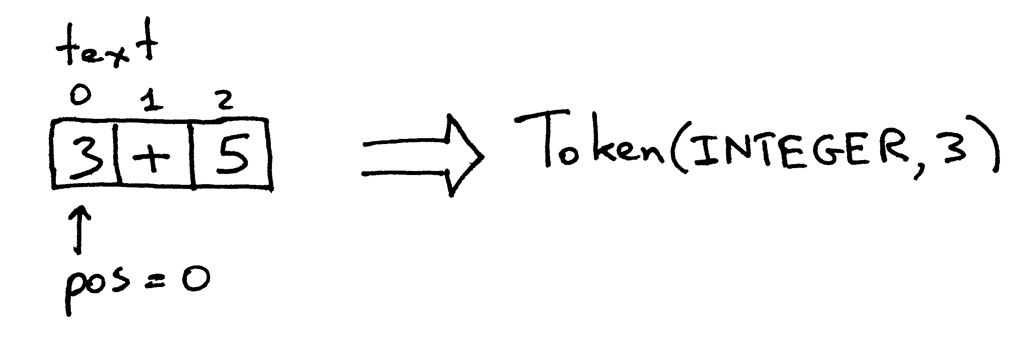
The method get_next_token of the Interpreter class is your lexical analyzer. Every time you call it, you get the next token created from the input of characters passed to the interpreter. Let’s take a closer look at the method itself and see how it actually does its job of converting characters into tokens. The input is stored in the variable text that holds the input string and pos is an index into that string (think of the string as an array of characters). pos is initially set to 0 and points to the character ‘3’. The method first checks whether the character is a digit and if so, it increments pos and returns a token instance with the type INTEGER and the value set to the integer value of the string ‘3’, which is an integer 3:
Interpreter 类的 get_next _ token 方法是词法分析器。每次调用它时,都会得到通过传递给解释器的字符输入创建的下一个token。让我们仔细研究一下这个方法本身,看看它实际上是如何将字符转换为token的。输入存储在变量text中,pos 是该字符串的索引(可以将字符串看作一个字符数组)。pos 最初设置为0,并指向字符“3”。该方法首先检查字符是否为数字,如果是,则递增 pos 并返回一个token实例,其类型为 INTEGER,值设置为字符串‘3’的整数值,即整数3:
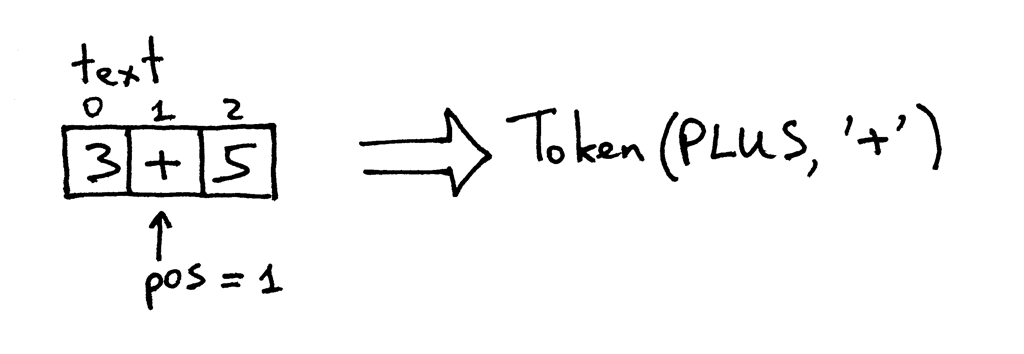
The pos now points to the ‘+’ character in the text. The next time you call the method, it tests if a character at the position pos is a digit and then it tests if the character is a plus sign, which it is. As a result the method increments pos and returns a newly created token with the type PLUS and value ‘+’:
pos现在指向文本中的“ +”字符。下次调用该方法时,它将检查位置 pos 处的字符是否为数字,然后检查该字符是否为加号(它确实是加号)。因此,该方法使pos自增并返回一个新创建的token,其类型为 PLUS,值为 ‘+’ :
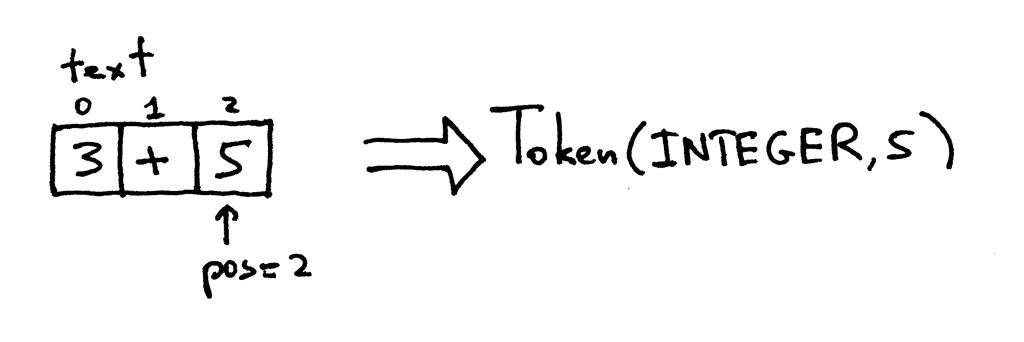
The pos now points to character ‘5’. When you call the get_next_token method again the method checks if it’s a digit, which it is, so it increments pos and returns a new INTEGER token with the value of the token set to integer 5:
pos现在指向字符“5”。当你再次调用 get _ next _ token 方法时,这个方法会检查它是否是一个数字,确实是一个数字,所以它会自增 pos 并返回一个新的 INTEGER token,其值设置为整数5:
Because the pos index is now past the end of the string “3+5” the get_next_token method returns the EOF token every time you call it:
因为 pos 索引现在已经超过了字符串“3 + 5”的结尾,所以 get _ next _ token 方法在每次调用它时都返回 EOF token:
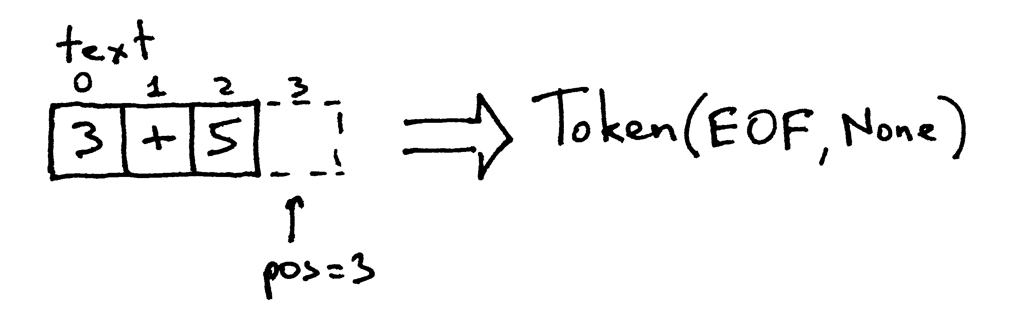
Try it out and see for yourself how the lexer component of your calculator works:
试一试,看看你的计算器的 lexer 组件是如何工作的:
So now that your interpreter has access to the stream of tokens made from the input characters, the interpreter needs to do something with it: it needs to find the structure in the flat stream of tokens it gets from the lexer get_next_token. Your interpreter expects to find the following structure in that stream: INTEGER -> PLUS -> INTEGER. That is, it tries to find a sequence of tokens: integer followed by a plus sign followed by an integer.
因此,既然你的解释器可以访问由输入字符转换的token流,那么解释器就需要对其进行处理: 它需要在通过词法分析器的get_next_token 获得的平面token流中找到结构。你的解释器期望在该流中找到以下结构: INTEGER-> PLUS-> INTEGER。也就是说,它试图找到一个token序列: 先是整数,然后是加号,最后是整数。
The method responsible for finding and interpreting that structure is expr. This method verifies that the sequence of tokens does indeed correspond to the expected sequence of tokens, i.e INTEGER -> PLUS -> INTEGER. After it’s successfully confirmed the structure, it generates the result by adding the value of the token on the left side of the PLUS and the right side of the PLUS, thus successfully interpreting the arithmetic expression you passed to the interpreter.
发现和解释该结构的方法是expr。此方法验证token序列确实与token的预期序列(即 INTEGER-> PLUS-> INTEGER)相对应。在成功地确认结构之后,它通过在 PLUS 的左侧和 PLUS 的右侧添加token值来生成结果,从而成功地解释传递给解释器的算术表达式。
The expr method itself uses the helper method eat to verify that the token type passed to the eat method matches the current token type. After matching the passed token type the eat method gets the next token and assigns it to the current_token variable, thus effectively “eating” the currently matched token and advancing the imaginary pointer in the stream of tokens. If the structure in the stream of tokens doesn’t correspond to the expected INTEGER PLUS INTEGER sequence of tokens the eat method throws an exception.
expr 方法本身使用 帮助方法 eat 来验证传递给 eat 方法的预期 token类型是否与当前token的类型匹配。如果匹配,则 eat 方法获取下一个token并将其赋值给当前的 current_token 变量,从而有效地“吃掉”当前匹配的token并在token流中推进“虚指针”(pos)。如果token流中的结构不符合预期的“INTEGER PLUS INTEGER”,则 eat 方法抛出异常。
Let’s recap what your interpreter does to evaluate an arithmetic expression:
让我们来回顾一下你的解释器是如何计算算术表达式的:
- The interpreter accepts an input string, let’s say “3+5”
解释器接受输入字符串,比如说“3 + 5” - The interpreter calls the expr method to find a structure in the stream of tokens returned by the lexical analyzer get_next_token. The structure it tries to find is of the form INTEGER PLUS INTEGER. After it’s confirmed the structure, it interprets the input by adding the values of two INTEGER tokens because it’s clear to the interpreter at that point that what it needs to do is add two integers, 3 and 5.
解释器调用expr方法来查找由词汇分析器的get_next_token返回的token流中的结构。它试图找到结构为“INTEGER PLUS INTEGER”的形式。在确认结构之后,它通过添加两个INTEGER toekn的值来解释输入,因为它在该点处对解释器清晰地表示,它需要做的是添加两个整数,3和5。
Congratulate yourself. You’ve just learned how to build your very first interpreter!
祝贺你自己,你刚刚学会了如何建立你的第一个解释器!
Now it’s time for exercises.
现在是练习的时间了。

You didn’t think you would just read this article and that would be enough, did you? Okay, get your hands dirty and do the following exercises:
你不会认为你只是读了这篇文章就足够了吧?好的,把你的手“弄脏”(emmm),做以下练习:
- Modify the code to allow multiple-digit integers in the input, for example “12+3”
修改代码以允许输入中有多个数字的整数,例如“12 + 3” - Add a method that skips whitespace characters so that your calculator can handle inputs with whitespace characters like ” 12 + 3”
添加跳过空格字符的方法,以便计算器可以处理空格字符(如“12 + 3”)的输入 - Modify the code and instead of ‘+’ handle ‘-‘ to evaluate subtractions like “7-5”
修改代码,用“ +”代替“-”来计算减法,比如“7-5”
我的答案:
Check your understanding
- What is an interpreter? 什么是翻译器?
是一种计算机程序,能够把解释型语言解释执行。解释器就像一位“中间人”。解释器边解释边执行,因此依赖于解释器的程序运行速度比较缓慢。
- What is a compiler? 什么是编译器?
- What’s the difference between an interpreter and a compiler? 解释器和编译器有什么区别?
- What is a token? 什么是token?
token是具有类型和值的对象
- What is the name of the process that breaks input apart into tokens? 将输入分解成toekn的的过程称是什么?
词法分析
- What is the part of the interpreter that does lexical analysis called? 解释器中词法分析的那部分是什么?
词法分析器
- What are the other common names for that part of an interpreter or a compiler? 解释器或编译器的这一部分的其他常用名称是什么?
扫描器或标记器
scanner or tokenizer
Before I finish this article, I really want you to commit to studying interpreters and compilers. And I want you to do it right now. Don’t put it on the back burner. Don’t wait. If you’ve skimmed the article, start over. If you’ve read it carefully but haven’t done exercises - do them now. If you’ve done only some of them, finish the rest. You get the idea. And you know what? Sign the commitment pledge to start learning about interpreters and compilers today!
在我完成这篇文章之前,我真的希望您能致力于研究解释器和编译器。我希望你现在就做。不要把它放在次要地位。不要等待。如果你已经浏览了这篇文章,那就重新开始细读。如果你已经仔细阅读了它,但是还没有做练习,那么现在就做。如果你只完成了其中的一部分,那就完成剩下的。签署承诺,今天就开始学习解释器和编译器!
I, **_****_****_****_**____, of being sound mind and body, do hereby pledge to commit to studying interpreters and compilers starting today and get to a point where I know 100% how they work!
我,作为一个身心健康的人,在此承诺从今天开始学习解释器和编译器,直到我完全了解它们是如何工作的!
Signature:
Date:

Sign it, date it, and put it somewhere where you can see it every day to make sure that you stick to your commitment. And keep in mind the definition of commitment:
签名,注明日期,并把它放在你每天都能看到的地方,以确保你遵守你的承诺。记住承诺的定义:
“Commitment is doing the thing you said you were going to do long after the mood you said it in has left you.” — Darren Hardy
“承诺就是在你所说的情绪离开你很久之后,仍然去做你所说的事情。”ー Darren Hardy
Okay, that’s it for today. In the next article of the mini series you will extend your calculator to handle more arithmetic expressions. Stay tuned.
好了,今天就到这里。在下一篇文章中,你将扩展计算器来处理更多的算术表达式。请继续关注。
If you can’t wait for the second article and are chomping at the bit to start digging deeper into interpreters and compilers, here is a list of books I recommend that will help you along the way:
如果你迫不及待地想看第二篇文章,迫不及待地开始深入研究解释器和编译器,这里有一个我推荐的书目列表,它们会一路帮助你:
- Language Implementation Patterns: Create Your Own Domain-Specific and General Programming Languages (Pragmatic Programmers)
语言实现模式: 创建您自己的特定领域和通用编程语言(实用程序员) - Writing Compilers and Interpreters: A Software Engineering Approach
编写编译器和解释器: 一种软件工程方法 - Modern Compiler Implementation in Java
现代编译器在 Java 中的实现 - Modern Compiler Design
现代编译器设计 - Compilers: Principles, Techniques, and Tools (2nd Edition)
编译器: 原理、技术和工具(第二版)
All articles in this series:
本系列的所有文章:
- Let's Build A Simple Interpreter. Part 1. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 2. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 3. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 4. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 5. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 6. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 7: Abstract Syntax Trees 让我们构建一个简单的解释器。第7部分: 抽象语法树
- Let's Build A Simple Interpreter. Part 8. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 9. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 10. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 11. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 12. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 13: Semantic Analysis 让我们建立一个简单的解释器。第13部分: 语义分析
- Let's Build A Simple Interpreter. Part 14: Nested Scopes and a Source-to-Source Compiler 让我们构建一个简单的解释器。第14部分: 嵌套作用域和源到源编译器
- Let's Build A Simple Interpreter. Part 15. 让我们构建一个简单的解释器。第15部分
- Let's Build A Simple Interpreter. Part 16: Recognizing Procedure Calls 让我们建立一个简单的解释器。第16部分: 识别过程调用
- Let's Build A Simple Interpreter. Part 17: Call Stack and Activation Records 让我们构建一个简单的解释器。第17部分: 调用堆栈和激活记录
- Let's Build A Simple Interpreter. Part 18: Executing Procedure Calls 让我们构建一个简单的解释器。第18部分: 执行过程调用
- Let's Build A Simple Interpreter. Part 19: Nested Procedure Calls 让我们构建一个简单的解释器。第19部分: 嵌套过程调用