“Be not afraid of going slowly; be afraid only of standing still.” - Chinese proverb.
“不怕慢,只怕原地踏步”——中国谚语。
Hello, and welcome back!
大家好,欢迎回来!
Today we are going to take a few more baby steps and learn how to parse Pascal procedure declarations.
今天,我们将走更多的baby step,并学习如何解析 Pascal 过程声明(procedure declarations)。

What is a procedure declaration? A procedure declaration is a language construct that defines an identifier (a procedure name) and associates it with a block of Pascal code.
什么是过程声明?过程声明是一种语言结构,它定义了一个标识符(过程名称) ,并将其与一组 Pascal 代码关联起来。
Before we dive in, a few words about Pascal procedures and their declarations:
在我们深入讨论之前,先简单介绍一下 Pascal 的procedures及其声明:
- Pascal procedures don’t have return statements. They exit when they reach the end of their corresponding block. Pascal
- 过程没有返回语句,它们在到达相应块的末尾时退出
- Pascal procedures can be nested within each other. Pascal
- 过程可以相互嵌套
- For simplicity reasons, procedure declarations in this article won’t have any formal parameters. But, don’t worry, we’ll cover that later in the series.
- 为了简单起见,本文中的过程声明没有任何形参。但是,不要担心,我们将在本系列的后面讨论这个问题。
This is our test program for today:
这是我们今天的测试程序:
PROGRAM Part12;
VAR
a : INTEGER;
PROCEDURE P1;
VAR
a : REAL;
k : INTEGER;
PROCEDURE P2;
VAR
a, z : INTEGER;
BEGIN {P2}
z := 777;
END; {P2}
BEGIN {P1}
END; {P1}
BEGIN {Part12}
a := 10;
END. {Part12}
As you can see above, we have defined two procedures (P1 and P2) and P2 is nested within P1. In the code above, I used comments with a procedure’s name to clearly indicate where the body of every procedure begins and where it ends.
正如您在上面看到的,我们已经定义了两个过程(P1和 P2) ,P2嵌套在 P1中。在上面的代码中,我使用带有过程名称的注释来清楚地指出每个过程的主体开始和结束的位置。
Our objective for today is pretty clear: learn how to parse a code like that.
我们今天的目标很明确: 学习如何解析这样的代码。
First, we need to make some changes to our grammar to add procedure declarations. Well, let’s just do that!
首先,我们需要对grammar进行一些修改,以添加过程声明!
Here is the updated declarations grammar rule:
下面是更新的 declarations grammar规则:

The procedure declaration sub-rule consists of the reserved keyword PROCEDURE followed by an identifier (a procedure name), followed by a semicolon, which in turn is followed by a block rule, which is terminated by a semicolon. Whoa! This is a case where I think the picture is actually worth however many words I just put in the previous sentence! 😃
过程声明子规则包括保留关键字 PROCEDURE 后跟标识符(过程名称) ,后跟分号,分号后跟block规则,以分号结束。哇!在这种情况下,无论我在前面的句子中加入多少字,我都认为图片是值得的!😃
Here is the updated syntax diagram for the declarations rule:
下面是更新后的declarations规则语法图:
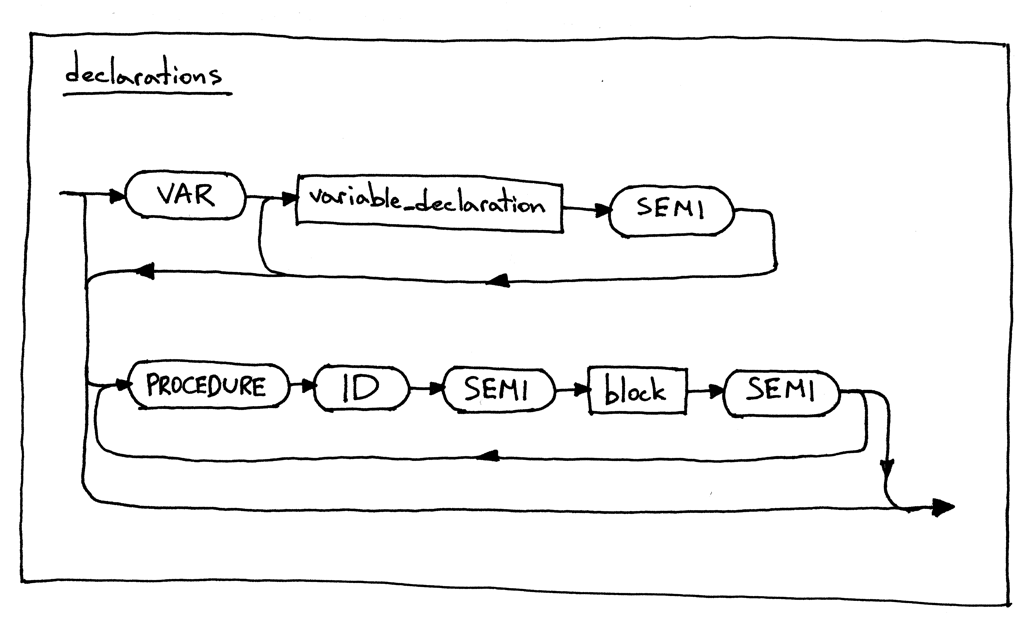
From the grammar and the diagram above you can see that you can have as many procedure declarations on the same level as you want. For example, in the code snippet below we define two procedure declarations, P1 and P1A, on the same level:
从上面的语法和图表中可以看到,您可以在同一级别上拥有任意多的过程声明。例如,在下面的代码片段中,我们在同一级别定义了两个过程声明,P1和 P1A:
PROGRAM Test;
VAR
a : INTEGER;
PROCEDURE P1;
BEGIN {P1}
END; {P1}
PROCEDURE P1A;
BEGIN {P1A}
END; {P1A}
BEGIN {Test}
a := 10;
END. {Test}
The diagram and the grammar rule above also indicate that procedure declarations can be nested because the procedure declaration sub-rule references the block rule which contains the declarations rule, which in turn contains the procedure declaration sub-rule. As a reminder, here is the syntax diagram and the grammar for the block rule from Part10:
上面的图和语法规则也表明过程declarations可以嵌套,因为过程declarations子规则引用了包含declarations规则的block规则,而block规则又包含过程declarations子规则。提醒一下,下面是第10部分中block规则的语法图和语法:

Okay, now let’s focus on the interpreter components that need to be updated to support procedure declarations:
好的,现在让我们关注一下需要更新以支持过程声明的解释器组件:
Updating the Lexer
更新 Lexer
All we need to do is add a new token named PROCEDURE:
我们所需要做的就是添加一个名为 PROCEDURE 的新token:
And add ‘PROCEDURE’ to the reserved keywords. Here is the complete mapping of reserved keywords to tokens:
然后在保留关键字上添加‘ PROCEDURE’,这里是保留关键字到token的完整映射:
RESERVED_KEYWORDS = {
'PROGRAM': Token('PROGRAM', 'PROGRAM'),
'VAR': Token('VAR', 'VAR'),
'DIV': Token('INTEGER_DIV', 'DIV'),
'INTEGER': Token('INTEGER', 'INTEGER'),
'REAL': Token('REAL', 'REAL'),
'BEGIN': Token('BEGIN', 'BEGIN'),
'END': Token('END', 'END'),
'PROCEDURE': Token('PROCEDURE', 'PROCEDURE'),
}
Updating the Parser
更新解析器
Here is a summary of the parser changes:
下面是解析器更改的摘要:
- New _ProcedureDecl _ AST node
新的_ProcedureDecl AST _节点
- Update to the parser’s _declarations _method to support procedure declarations
更新解析器的declarations方法来支持过程声明
Let’s go over the changes.
我们来复习一下这些改动。
- The ProcedureDecl AST node represents a procedure declaration. The class constructor takes as parameters the name of the procedure and the AST node of the block of code that the procedure’s name refers to.
ProcedureDecl AST 节点表示一个过程声明。类构造函数接受procedure的名称和procedure名称引用的代码块的 AST 节点作为参数。
class ProcedureDecl(AST):
def __init__(self, proc_name, block_node):
self.proc_name = proc_name
self.block_node = block_node
- Here is the updated declarations method of the Parser class
下面是 Parser 类的更新声明方法
def declarations(self):
"""declarations : VAR (variable_declaration SEMI)+
| (PROCEDURE ID SEMI block SEMI)*
| empty
"""
declarations = []
if self.current_token.type == VAR:
self.eat(VAR)
while self.current_token.type == ID:
var_decl = self.variable_declaration()
declarations.extend(var_decl)
self.eat(SEMI)
while self.current_token.type == PROCEDURE:
self.eat(PROCEDURE)
proc_name = self.current_token.value
self.eat(ID)
self.eat(SEMI)
block_node = self.block()
proc_decl = ProcedureDecl(proc_name, block_node)
declarations.append(proc_decl)
self.eat(SEMI)
return declarations
Hopefully, the code above is pretty self-explanatory. It follows the grammar/syntax diagram for procedure declarations that you’ve seen earlier in the article.
希望上面的代码非常容易理解。它遵循您在本文前面看到的过程声明的语法/语法图。
Updating the SymbolTable builder
更新 SymbolTable 生成器
Because we’re not ready yet to handle nested procedure scopes, we’ll simply add an empty visit_ProcedureDecl method to the SymbolTreeBuilder AST visitor class. We’ll fill it out in the next article.
因为我们还没有准备好处理嵌套的 procedure 域,我们只需要向_SymbolTreeBuilder AST visitor类添加一个空的_ _visit_ProcedureDecl _方法。我们将在下一篇文章中填写它。
def visit_ProcedureDecl(self, node):
pass
Updating the Interpreter
更新解释器
We also need to add an empty visit_ProcedureDecl method to the Interpreter class, which will cause our interpreter to silently ignore all our procedure declarations.
我们还需要在 Interpreter 类中添加一个空的 visit_ProcedureDecl 方法,这将导致我们的解释器静默地忽略所有的过程声明。
So far, so good.
到目前为止,一切顺利。
Now that we’ve made all the necessary changes, let’s see what the Abstract Syntax Tree looks like with the new ProcedureDecl nodes.
现在我们已经做了所有必要的修改,让我们来看看使用新的 ProcedureDecl 节点后的抽象语法树是什么样的。
Here is our Pascal program again (you can download it directly from GitHub):
下面是我们的 Pascal 程序(你可以直接从 GitHub 下载) :
PROGRAM Part12;
VAR
a : INTEGER;
PROCEDURE P1;
VAR
a : REAL;
k : INTEGER;
PROCEDURE P2;
VAR
a, z : INTEGER;
BEGIN {P2}
z := 777;
END; {P2}
BEGIN {P1}
END; {P1}
BEGIN {Part12}
a := 10;
END. {Part12}
Let’s generate an AST and visualize it with the genastdot.py utility:
让我们生成一个 AST,并使用 genastdot.py 实用程序将其可视化:
$ python genastdot.py part12.pas > ast.dot && dot -Tpng -o ast.png ast.dot
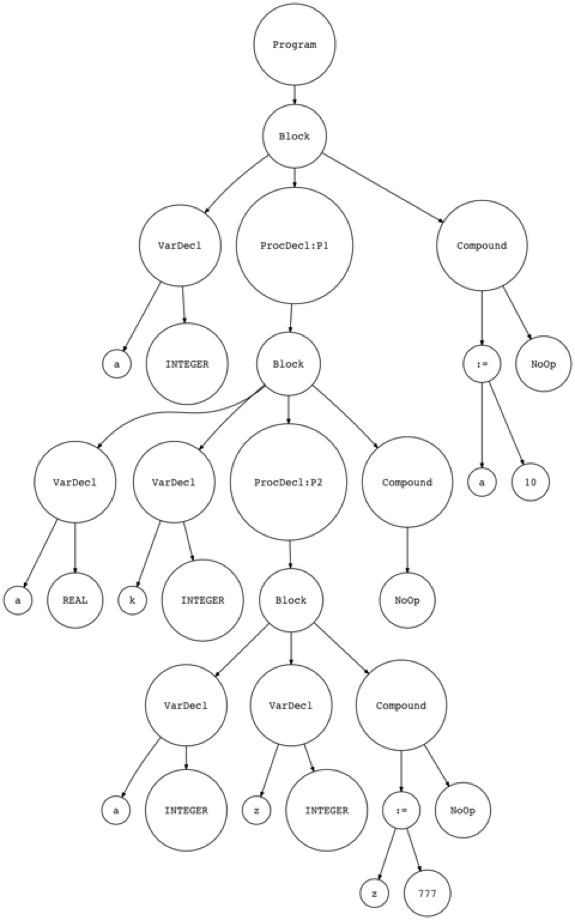
In the picture above you can see two ProcedureDecl nodes: ProcDecl:P1 and ProcDecl:P2 that correspond to procedures P1 and P2. Mission accomplished. 😃
在上面的图片中,您可以看到两个 ProcedureDecl 节点: ProcDecl: P1和 ProcDecl: P2,它们对应于过程 P1和 P2。任务完成。😃
As a last item for today, let’s quickly check that our updated interpreter works as before when a Pascal program has procedure declarations in it. Download the interpreter and the test program if you haven’t done so yet, and run it on the command line. Your output should look similar to this:
作为今天的最后一项,让我们快速检查一下,当 Pascal 程序中包含过程声明时,我们更新的解释器是否像以前一样工作。下载解释器和测试程序(如果您还没有这样做的话) ,并在命令行上运行它。你的输出应该类似于这样:
$ python spi.py part12.pas
Define: INTEGER
Define: REAL
Lookup: INTEGER
Define: <a:INTEGER>
Lookup: a
Symbol Table contents:
Symbols: [INTEGER, REAL, <a:INTEGER>]
Run-time GLOBAL_MEMORY contents:
a = 10
Okay, with all that knowledge and experience under our belt, we’re ready to tackle the topic of nested scopes that we need to understand in order to be able to analyze nested procedures and prepare ourselves to handle procedure and function calls. And that’s exactly what we are going to do in the next article: dive deep into nested scopes. So don’t forget to bring your swimming gear next time! Stay tuned and see you soon!
好的,有了这些知识和经验,我们已经准备好处理嵌套作用域的主题,我们需要理解这些作用域,以便能够分析嵌套的过程,并为处理过程和函数调用做好准备。这正是我们在下一篇文章中要做的: 深入探究嵌套域。所以下次别忘了带上你的游泳装备!请继续关注,我们很快就会再见!
All articles in this series:
本系列的所有文章:
- Let's Build A Simple Interpreter. Part 1. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 2. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 3. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 4. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 5. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 6. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 7: Abstract Syntax Trees 让我们构建一个简单的解释器。第7部分: 抽象语法树
- Let's Build A Simple Interpreter. Part 8. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 9. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 10. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 11. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 12. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 13: Semantic Analysis
- Let's Build A Simple Interpreter. Part 14: Nested Scopes and a Source-to-Source Compiler
- Let's Build A Simple Interpreter. Part 15.
- Let's Build A Simple Interpreter. Part 16: Recognizing Procedure Calls
- Let's Build A Simple Interpreter. Part 17: Call Stack and Activation Records
- Let's Build A Simple Interpreter. Part 18: Executing Procedure Calls
- Let's Build A Simple Interpreter. Part 19: Nested Procedure Calls