I was sitting in my room the other day and thinking about how much we had covered, and I thought I would recap what we’ve learned so far and what lies ahead of us.
有一天,我坐在房间里,想着我们学了多少东西,我想我应该重述一下我们到目前为止学到的东西,以及我们将要学到的东西。

Up until now we’ve learned:
到目前为止,我们已经了解到:
- How to break sentences into tokens. The process is called lexical analysis and the part of the interpreter that does it is called a lexical analyzer, lexer, scanner, or tokenizer. We’ve learned how to write our own lexer from the ground up without using regular expressions or any other tools like Lex.
- 如何将sentences分解成token。这个过程叫 词法分析,解释器的负责这部分的叫做 lexical analyzer, lexer, scanner, or tokenizer。
- How to recognize a phrase in the stream of tokens. The process of recognizing a phrase in the stream of tokens or, to put it differently, the process of finding structure in the stream of tokens is called parsing or syntax analysis. The part of an interpreter or compiler that performs that job is called a parser or syntax analyzer.
- 如何在token流中识别一个phrase,或者说如何在token流中找到一个结构。这个过程叫做parsing或者syntax analysis(解析或者语法分析)。解释器负责这部分的叫做 parser 或者 syntax analyzer。
- How to represent a programming language’s syntax rules with syntax diagrams, which are a graphical representation of a programming language’s syntax rules. Syntax diagrams visually show us which statements are allowed in our programming language and which are not.
- 如何用语法图表示一个编程语言的syntax规则。语法图可视化显示哪些语句是允许的,哪些是不允许的。
- How to use another widely used notation for specifying the syntax of a programming language. It’s called context-free grammars (grammars, for short) or BNF (Backus-Naur Form).
- 如何使用另一种广泛使用的表示法来指定编程语言的syntax。被称为 上下文无关文法(grammars)或者_BNF_ (Backus-Naur Form)。
- How to map a grammar to code and how to write a recursive-descent parser.
- 如何将grammar映射到code,以及如何写一个递归下降解析器。
- How to write a really basic interpreter.
- 如何写一个真正的基础的解释器
- How associativity and precedence of operators work and how to construct a grammar using a precedence table.
- 操作符的结合性和优先级如何工作,以及如何使用优先表构造语法。
- How to build an Abstract Syntax Tree (AST) of a parsed sentence and how to represent the whole source program in Pascal as one big AST.
- 如何构造一个parsed sentence 的 AST,以及如何表示在一个AST中表示Pascal的整个源码项目。
- How to walk an AST and how to implement our interpreter as an AST node visitor.
- 如何遍历AST,以及如何在我们的解释器中实现一个AST节点visitor。
With all that knowledge and experience under our belt, we’ve built an interpreter that can scan, parse, and build an AST and interpret, by walking the AST, our very first complete Pascal program. Ladies and gentlemen, I honestly think if you’ve reached this far, you deserve a pat on the back. But don’t let it go to your head. Keep going. Even though we’ve covered a lot of ground, there are even more exciting parts coming our way.
凭借我们所有的知识和经验,我们已经建立了一个解释器,它可以扫描、解析和构建一个 AST,并通过遍历 AST 来解释,这是我们第一个完整的 Pascal 程序。女士们,先生们,我真诚地认为,如果你们已经走到了这一步,你们应该得到鼓励。但是不要让它冲昏了你的头脑。继续。尽管我们已经涉及了很多领域,但还有更多令人兴奋的部分正在向我们走来。
With everything we’ve covered so far, we are almost ready to tackle topics like:
到目前为止,我们已经涵盖了所有的内容,我们几乎已经准备好处理以下主题:
- Nested procedures and functions
- 嵌套的过程和函数
- Procedure and function calls
- 过程和函数调用
- Semantic analysis (type checking, making sure variables are declared before they are used, and basically checking if a program makes sense)
- 语义分析(类型检查,确保在使用变量之前声明它们,基本上检查程序是否有意义)
- Control flow elements (like IF statements)
- 控制流元素(如 IF 语句)
- Aggregate data types (Records)
- 聚合数据类型(记录)
- More built-in types
- 更多内置类型
- Source-level debugger
- 源代码级调试器
- Miscellanea (All the other goodness not mentioned above 😃
- 杂集(上面没有提到的所有其他的goodness:)
But before we cover those topics, we need to build a solid foundation and infrastructure.
但是在我们讨论这些主题之前,我们需要建立一个坚实的 foundation 和 infrastructure(基础架构)。
This is where we start diving deeper into the super important topic of symbols, symbol tables, and scopes. The topic itself will span several articles. It’s that important and you’ll see why. Okay, let’s start building that foundation and infrastructure, then, shall we?
我们从这里开始更深入地探讨符号、符号表和 域 这些超级重要的主题。这个主题本身将跨越几篇文章。这很重要,你会明白为什么的。好的,我们开始建造地基和基础架构,好吗?
First, let’s talk about symbols and why we need to track them. What is a symbol? For our purposes, we’ll informally define symbol as an identifier of some program entity like a variable, subroutine, or built-in type. For symbols to be useful they need to have at least the following information about the program entities they identify:
首先,让我们讨论一下符号以及为什么我们需要跟踪它们。什么是符号?出于我们的目的,我们将非正式地将 symbol 定义为某些程序实体(如变量、子例程或内置类型)的标识符。要使符号有用,它们至少需要有关于它们所识别的程序实体的下列信息:
- Name (for example, ‘x’, ‘y’, ‘number’)
- Name (例如,‘ x’、‘ y’、‘ number’)
- Category (Is it a variable, subroutine, or built-in type?)
- Category(它是变量、子例程还是内置类型?)
- Type (INTEGER, REAL)
- ( Type( 整数, 实数)
Today we’ll tackle variable symbols and built-in type symbols because we’ve already used variables and types before. By the way, the “built-in” type just means a type that hasn’t been defined by you and is available for you right out of the box, like INTEGER and REAL types that you’ve seen and used before.
今天我们将讨论变量符号和内置type符号,因为我们以前已经使用过变量和type。顺便说一下,“内置”type只是指一种您没有定义,并可以立即使用的type,比如您以前看到和使用过的 INTEGER 和 REAL type。
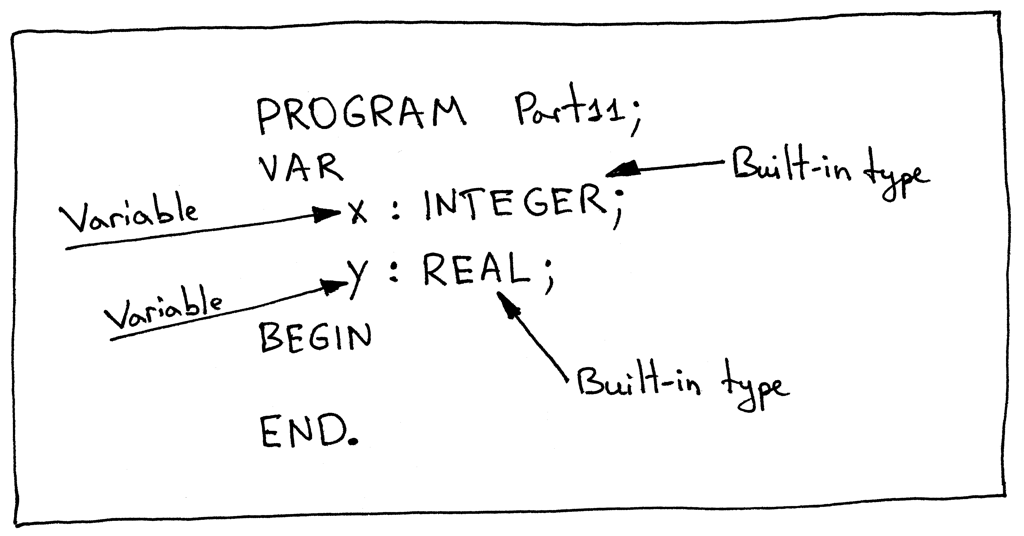
Let’s take a look at the following Pascal program, specifically at the variable declaration part. You can see in the picture below that there are four symbols in that section: two variable symbols (x and y) and two built-in type symbols (INTEGER and REAL).
让我们看看下面的 Pascal 程序,特别是变量声明部分。您可以在下面的图片中看到该部分中有四个符号: 两个变量符号(x 和 y)和两个内置type符号(INTEGER 和 REAL)。
How can we represent symbols in code? Let’s create a base Symbol class in Python:
如何在代码中表示符号? 让我们用 Python 创建一个基本的 Symbol 类:
class Symbol(object):
def __init__(self, name, type=None):
self.name = name
self.type = type
As you can see, the class takes the name parameter and an optional type parameter (not all symbols may have a type associated with them). What about the category of a symbol? We’ll encode the category of a symbol in the class name itself, which means we’ll create separate classes to represent different symbol categories.
如您所见,该类接受 name 参数和一个可选 type 参数(并非所有符号都可能具有与其关联的type)。那么符号的category呢?我们将在类名本身中对符号的category进行编码,这意味着我们将创建单独的类来表示不同的符号category。
Let’s start with basic built-in types. We’ve seen two built-in types so far, when we declared variables: INTEGER and REAL. How do we represent a built-in type symbol in code? Here is one option:
让我们从基本的内置type开始。到目前为止,在声明变量时,我们已经看到了两个内置类型: INTEGER 和 REAL。如何在代码中表示内置类型符号?这里有一个选择:
class BuiltinTypeSymbol(Symbol):
def __init__(self, name):
super().__init__(name)
def __str__(self):
return self.name
__repr__ = __str__
The class inherits from the Symbol class and the constructor requires only a name of the type. The category is encoded in the class name, and the type parameter from the base class for a built-in type symbol is None. The double underscore or dunder (as in “Double UNDERscore”) methods str and repr are special Python methods and we’ve defined them to have a nice formatted message when you print a symbol object.
类继承自 Symbol 类,构造函数只需要type的名称。category编码在类名中,内置type符号的基类的type参数为 None。双下划线或者 dunder (如“双下划线”)方法 str 和 repr 是特殊的 Python 方法,我们已经定义它们在打印符号对象时有一个漂亮的格式化消息。
Download the interpreter file and save it as spi.py; launch a python shell from the same directory where you saved the spi.py file, and play with the class we’ve just defined interactively:
下载解释器文件并将其保存为 spi.py; 从保存 spi.py 文件的同一个目录启动 python shell,并以交互方式使用我们刚刚定义的类:
$ python
>>> from spi import BuiltinTypeSymbol
>>> int_type = BuiltinTypeSymbol('INTEGER')
>>> int_type
INTEGER
>>> real_type = BuiltinTypeSymbol('REAL')
>>> real_type
REAL
How can we represent a variable symbol? Let’s create a VarSymbol class:
如何表示变量符号? 让我们创建一个 VarSymbol 类:
class VarSymbol(Symbol):
def __init__(self, name, type):
super().__init__(name, type)
def __str__(self):
return '<{name}:{type}>'.format(name=self.name, type=self.type)
__repr__ = __str__
In the class we made both the name and the type parameters required parameters and the class name VarSymbol clearly indicates that an instance of the class will identify a variable symbol (the category is variable.)
在类中,我们同时创建了name和type参数所需的参数,类名 VarSymbol 清楚地表明类的实例将识别一个变量符号(category是变量)
Back to the interactive python shell to see how we can manually construct instances for our variable symbols now that we know how to construct BuiltinTypeSymbol class instances:
回到交互式 python shell,看看既然我们已经知道如何构造_BuiltinTypeSymbol_类实例,那如何手动构建变量符号的实例:
$ python
>>> from spi import BuiltinTypeSymbol, VarSymbol
>>> int_type = BuiltinTypeSymbol('INTEGER')
>>> real_type = BuiltinTypeSymbol('REAL')
>>>
>>> var_x_symbol = VarSymbol('x', int_type)
>>> var_x_symbol
<x:INTEGER>
>>> var_y_symbol = VarSymbol('y', real_type)
>>> var_y_symbol
<y:REAL>
As you can see, we first create an instance of a built-in type symbol and then pass it as a parameter to VarSymbol‘s constructor.
如您所见,我们首先创建一个内置type符号的实例,然后将其作为参数传递给 VarSymbol 的构造函数。
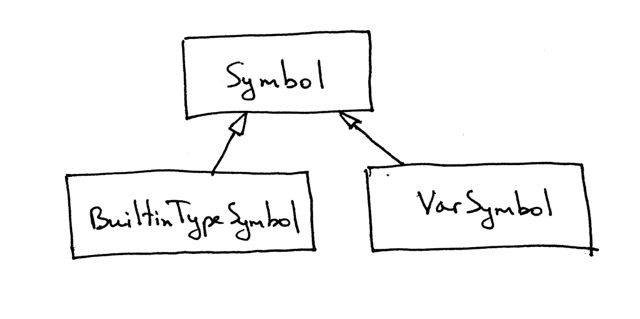
Here is the hierarchy of symbols we’ve defined in visual form:
下面是我们以视觉形式定义的符号层次:
So far so good, but we haven’t answered the question yet as to why we even need to track those symbols in the first place.
到目前为止还不错,但是我们还没有回答为什么我们需要首先追踪这些符号的问题。
Here are some of the reasons:
以下是一些原因:
- To make sure that when we assign a value to a variable the types are correct (type checking)
- 为了确保在给变量赋值时,类型是正确的(类型检查)
- To make sure that a variable is declared before it is used
- 确保在使用变量之前声明该变量
Take a look at the following incorrect Pascal program, for example:
看看下面这个不正确的 Pascal 程序,例如:
There are two problems with the program above (you can compile it with fpc to see it for yourself):
上面这个程序有两个问题(你可以用 fpc 编译它,自己看看) :
- In the expression _“x := 2 + y;” _ we assigned a decimal value to the variable “x” that was declared as integer. That wouldn’t compile because the types are incompatible.
在短语_x := 2 + y;_中,我们给声明为整数的变量“ x”赋了一个实数值。因为类型不兼容,所以不能编译
- In the assignment statement _“x := a;” _we referenced the variable “a” that wasn’t declared - wrong!
在赋值语句_x := a;_中,我们引用了未被声明的变量“ a”
To be able to identify cases like that even before interpreting/evaluating the source code of the program at run-time, we need to track program symbols. And where do we store the symbols that we track? I think you’ve guessed it right - in the symbol table!
为了能够在运行时解释/评估程序的源代码之前识别这样的情况,我们需要跟踪程序符号。我们在哪里存储我们追踪的符号?我想你已经猜对了——在符号表里!
What is a symbol table? A symbol table is an abstract data type (ADT) for tracking various symbols in source code. Today we’re going to implement our symbol table as a separate class with some helper methods:
什么是符号表?符号表是一个用于跟踪源代码中各种符号的抽象数据类型(ADT)。今天我们将使用一些 helper 方法将我们的符号表作为一个单独的类来实现:
class SymbolTable(object):
def __init__(self):
self._symbols = {}
def __str__(self):
s = 'Symbols: {symbols}'.format(
symbols=[value for value in self._symbols.values()]
)
return s
__repr__ = __str__
def define(self, symbol):
print('Define: %s' % symbol)
self._symbols[symbol.name] = symbol
def lookup(self, name):
print('Lookup: %s' % name)
symbol = self._symbols.get(name)
# 'symbol' is either an instance of the Symbol class or 'None'
return symbol
There are two main operations that we will be performing with the symbol table: storing symbols and looking them up by name: hence, we need two helper methods - define and lookup.
我们将使用符号表执行两个主要操作: 存储符号并按名称查找它们: 因此,我们需要两个helper 方法—— define 和 lookup。
The method define takes a symbol as a parameter and stores it internally in its _symbols ordered dictionary using the symbol’s name as a key and the symbol instance as a value. The method lookup takes a symbol name as a parameter and returns a symbol if it finds it or “None” if it doesn’t.
方法 define 将符号作为参数,并将其存储在符号名作为键和符号实例作为值的 _symbols 有序字典中。方法 lookup 接受一个符号名作为参数,如果找到它就返回一个符号,如果找不到就返回“ None”。
Let’s manually populate our symbol table for the same Pascal program we’ve used just recently where we were manually creating variable and built-in type symbols:
让我们为最近使用的 Pascal 程序手动填充符号表,我们手动创建变量和内置类型符号:
PROGRAM Part11;
VAR
x : INTEGER;
y : REAL;
BEGIN
END.
Launch a Python shell again and follow along:
再次启动一个 Python shell,然后执行以下操作:
$ python
>>> from spi import SymbolTable, BuiltinTypeSymbol, VarSymbol
>>> symtab = SymbolTable()
>>> int_type = BuiltinTypeSymbol('INTEGER')
>>> symtab.define(int_type)
Define: INTEGER
>>> symtab
Symbols: [INTEGER]
>>>
>>> var_x_symbol = VarSymbol('x', int_type)
>>> symtab.define(var_x_symbol)
Define: <x:INTEGER>
>>> symtab
Symbols: [INTEGER, <x:INTEGER>]
>>>
>>> real_type = BuiltinTypeSymbol('REAL')
>>> symtab.define(real_type)
Define: REAL
>>> symtab
Symbols: [INTEGER, <x:INTEGER>, REAL]
>>>
>>> var_y_symbol = VarSymbol('y', real_type)
>>> symtab.define(var_y_symbol)
Define: <y:REAL>
>>> symtab
Symbols: [INTEGER, <x:INTEGER>, REAL, <y:REAL>]
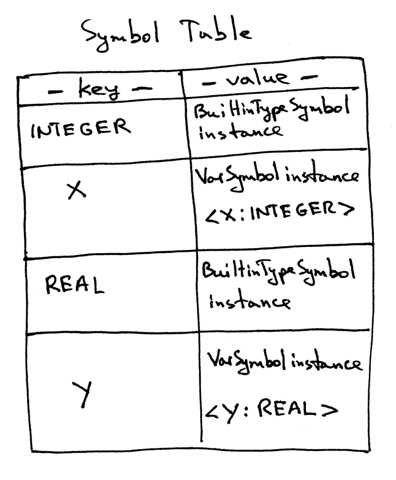
If you looked at the contents of the _symbols dictionary it would look something like this:
如果你查看一下这个符号字典的内容,你会发现:
How do we automate the process of building the symbol table? We’ll just write another node visitor that walks the AST built by our parser! This is another example of how useful it is to have an intermediary form like AST. Instead of extending our parser to deal with the symbol table, we separate concerns and write a new node visitor class. Nice and clean. 😃
我们如何将构建符号表的过程自动化?只需要编写另一个节点 visitor 来访问由解析器构建的 AST!这是另一个例子,说明使用类似 AST 的中间表示是多么有用。我们没有扩展解析器来处理符号表,而是分离关注点并编写一个新的节点visitor类。漂亮又干净。😃
Before doing that, though, let’s extend our SymbolTable class to initialize the built-in types when the symbol table instance is created. Here is the full source code for today’s SymbolTable class:
但是,在此之前,让我们扩展 SymbolTable 类,以便在创建符号表实例时初始化内置type。下面是今天的 SymbolTable 类的完整源代码:
class SymbolTable(object):
def __init__(self):
self._symbols = OrderedDict()
self._init_builtins()
def _init_builtins(self):
self.define(BuiltinTypeSymbol('INTEGER'))
self.define(BuiltinTypeSymbol('REAL'))
def __str__(self):
s = 'Symbols: {symbols}'.format(
symbols=[value for value in self._symbols.values()]
)
return s
__repr__ = __str__
def define(self, symbol):
print('Define: %s' % symbol)
self._symbols[symbol.name] = symbol
def lookup(self, name):
print('Lookup: %s' % name)
symbol = self._symbols.get(name)
# 'symbol' is either an instance of the Symbol class or 'None'
return symbol
Now onto the SymbolTableBuilder AST node visitor:
现在到 SymbolTableBuilder AST 节点visitor:
class SymbolTableBuilder(NodeVisitor):
def __init__(self):
self.symtab = SymbolTable()
def visit_Block(self, node):
for declaration in node.declarations:
self.visit(declaration)
self.visit(node.compound_statement)
def visit_Program(self, node):
self.visit(node.block)
def visit_BinOp(self, node):
self.visit(node.left)
self.visit(node.right)
def visit_Num(self, node):
pass
def visit_UnaryOp(self, node):
self.visit(node.expr)
def visit_Compound(self, node):
for child in node.children:
self.visit(child)
def visit_NoOp(self, node):
pass
def visit_VarDecl(self, node):
type_name = node.type_node.value
type_symbol = self.symtab.lookup(type_name)
var_name = node.var_node.value
var_symbol = VarSymbol(var_name, type_symbol)
self.symtab.define(var_symbol)
You’ve seen most of those methods before in the Interpreter class, but the visit_VarDecl method deserves some special attention. Here it is again:
你以前在 Interpreter 类中见过这些方法中的大多数,但是 visit_VarDecl 方法值得特别注意。再看看:
def visit_VarDecl(self, node):
type_name = node.type_node.value
type_symbol = self.symtab.lookup(type_name)
var_name = node.var_node.value
var_symbol = VarSymbol(var_name, type_symbol)
self.symtab.define(var_symbol)
This method is responsible for visiting (walking) a VarDecl AST node and storing the corresponding symbol in the symbol table. First, the method looks up the built-in type symbol by name in the symbol table, then it creates an instance of the VarSymbol class and stores (defines) it in the symbol table.
此方法负责访问(遍历) VarDecl AST 节点并将相应的符号存储在符号表中。首先,该方法在 symbol 表中按名称查找内置type符号,然后创建 VarSymbol 类的实例,并将其存储(定义)到 symbol 表中。
Let’s take our SymbolTableBuilder AST walker for a test drive and see it in action:
让我们用 SymbolTableBuilder AST walker 作为一个测试驱动器,看看它是如何运行的:
$ python
>>> from spi import Lexer, Parser, SymbolTableBuilder
>>> text = """
... PROGRAM Part11;
... VAR
... x : INTEGER;
... y : REAL;
...
... BEGIN
...
... END.
... """
>>> lexer = Lexer(text)
>>> parser = Parser(lexer)
>>> tree = parser.parse()
>>> symtab_builder = SymbolTableBuilder()
Define: INTEGER
Define: REAL
>>> symtab_builder.visit(tree)
Lookup: INTEGER
Define: <x:INTEGER>
Lookup: REAL
Define: <y:REAL>
>>> # Let’s examine the contents of our symbol table
…
>>> symtab_builder.symtab
Symbols: [INTEGER, REAL, <x:INTEGER>, <y:REAL>]
In the interactive session above, you can see the sequence of “Define: …” and “Lookup: …” messages that indicate the order in which symbols are defined and looked up in the symbol table. The last command in the session prints the contents of the symbol table and you can see that it’s exactly the same as the contents of the symbol table that we’ve built manually before. The magic of AST node visitors is that they pretty much do all the work for you. 😃
在上面的交互式会话中,您可以看到“ Define: ...”和“ Lookup: ...”消息的顺序,它们指示在符号表中定义和查找符号的顺序。会话中的最后一个命令输出 symbol 表的内容,您可以看到它与我们之前手动构建的 symbol 表的内容完全相同。AST 节点visitor 的神奇之处在于,他们几乎为您完成了所有的工作。😃
We can already put our symbol table and symbol table builder to good use: we can use them to verify that variables are declared before they are used in assignments and expressions. All we need to do is just extend the visitor with two more methods: visit_Assign and visit_Var:
我们已经可以很好地使用我们的符号表和符号表构建器: 我们可以使用它们来验证变量在用于赋值和表达式之前是否已经声明了。我们需要做的只是用两个方法扩展visitor: visit_Assign 和visit_Var:
def visit_Assign(self, node):
var_name = node.left.value # 获取node的左子节点的变量名,即赋值表达式左边的变量的name
var_symbol = self.symtab.lookup(var_name) # 在符号表搜索符号
if var_symbol is None:
raise NameError(repr(var_name))
self.visit(node.right)
def visit_Var(self, node):
var_name = node.value
var_symbol = self.symtab.lookup(var_name)
if var_symbol is None:
raise NameError(repr(var_name))
These methods will raise a NameError exception if they cannot find the symbol in the symbol table.
如果这些方法无法在符号表中找到符号,则会引发 NameError 异常。
Take a look at the following program, where we reference the variable “b” that hasn’t been declared yet:
看看下面的程序,我们引用了一个尚未声明的变量“ b”:
PROGRAM NameError1;
VAR
a : INTEGER;
BEGIN
a := 2 + b;
END.
Let’s see what happens if we construct an AST for the program and pass it to our symbol table builder to visit:
让我们看看如果我们为程序构造一个 AST 并将其传递给我们的符号表构建器以访问它会发生什么:
$ python
>>> from spi import Lexer, Parser, SymbolTableBuilder
>>> text = """
... PROGRAM NameError1;
... VAR
... a : INTEGER;
...
... BEGIN
... a := 2 + b;
... END.
... """
>>> lexer = Lexer(text)
>>> parser = Parser(lexer)
>>> tree = parser.parse()
>>> symtab_builder = SymbolTableBuilder()
Define: INTEGER
Define: REAL
>>> symtab_builder.visit(tree)
Lookup: INTEGER
Define: <a:INTEGER>
Lookup: a
Lookup: b
Traceback (most recent call last):
...
File "spi.py", line 674, in visit_Var
raise NameError(repr(var_name))
NameError: 'b'
Exactly what we were expecting!
这正是我们所期待的!
Here is another error case where we try to assign a value to a variable that hasn’t been defined yet, in this case the variable ‘a’:
下面是另一个错误的例子,我们试图给一个尚未定义的变量赋值,在这个例子中,变量 a:
PROGRAM NameError2;
VAR
b : INTEGER;
BEGIN
b := 1;
a := b + 2;
END.
Meanwhile, in the Python shell:
同时,在 Python shell 中:
>>> from spi import Lexer, Parser, SymbolTableBuilder
>>> text = """
... PROGRAM NameError2;
... VAR
... b : INTEGER;
...
... BEGIN
... b := 1;
... a := b + 2;
... END.
... """
>>> lexer = Lexer(text)
>>> parser = Parser(lexer)
>>> tree = parser.parse()
>>> symtab_builder = SymbolTableBuilder()
Define: INTEGER
Define: REAL
>>> symtab_builder.visit(tree)
Lookup: INTEGER
Define: <b:INTEGER>
Lookup: b
Lookup: a
Traceback (most recent call last):
...
File "spi.py", line 665, in visit_Assign
raise NameError(repr(var_name))
NameError: 'a'
Great, our new visitor caught this problem too!
太好了,我们的新visitor也检测到了这个问题!
I would like to emphasize the point that all those checks that our SymbolTableBuilder AST visitor makes are made before the run-time, so before our interpreter actually evaluates the source program. To drive the point home if we were to interpret the following program:
我想强调的一点是,我们的 SymbolTableBuilder AST visitor 所做的所有检查都是在运行时之前进行的,因此是在我们的解释器实际评估源程序之前。如果我们要解释下面的程序,就要把这一点说清楚:
PROGRAM Part11;
VAR
x : INTEGER;
BEGIN
x := 2;
END.
The contents of the symbol table and the run-time GLOBAL_MEMORY right before the program exited would look something like this:
在程序退出之前,符号表和运行时 GLOBAL_MEMORY 的内容如下:
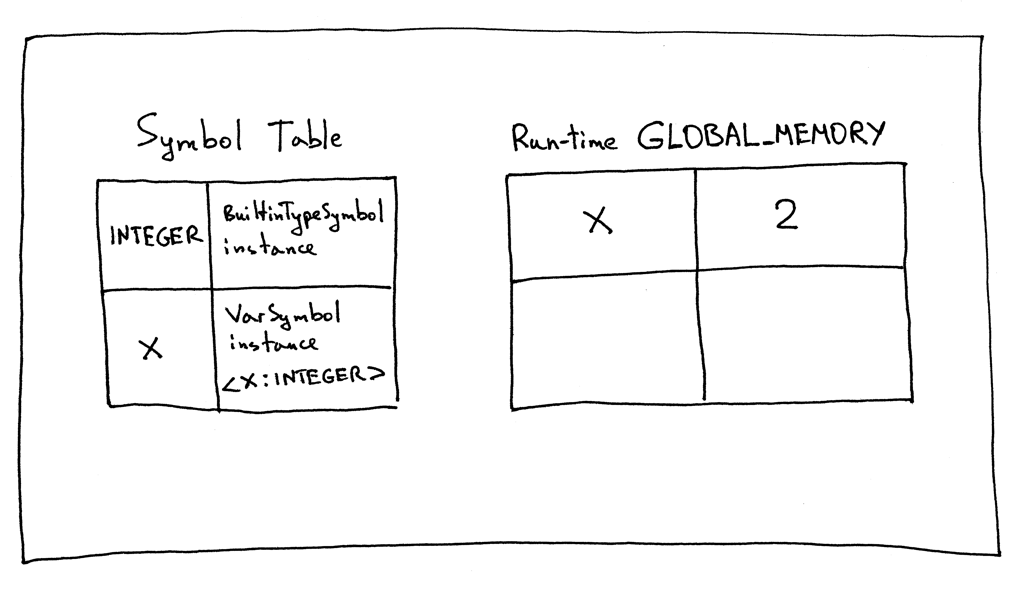
Do you see the difference? Can you see that the symbol table doesn’t hold the value 2 for variable “x”? That’s solely the interpreter’s job now.
你看出区别了吗?你能看到符号表中不包含变量“ x”的值2吗?这现在完全是翻译的工作了。
Remember the picture from Part 9 where the Symbol Table was used as global memory?
还记得第9部分中的图片吗,其中使用符号表作为全局内存?
No more! We effectively got rid of the hack where symbol table did double duty as global memory.
我们有效地解决了符号表作为全局内存的双重作用的hack问题。
Let’s put it all together and test our new interpreter with the following program:
让我们把它们放在一起,用下面的程序测试我们的新解释器:
PROGRAM Part11;
VAR
number : INTEGER;
a, b : INTEGER;
y : REAL;
BEGIN {Part11}
number := 2;
a := number ;
b := 10 * a + 10 * number DIV 4;
y := 20 / 7 + 3.14
END. {Part11}
Save the program as part11.pas and fire up the interpreter:
将程序保存为 part11.pas 并启动解释器:
$ python spi.py part11.pas
Define: INTEGER
Define: REAL
Lookup: INTEGER
Define: <number:INTEGER>
Lookup: INTEGER
Define: <a:INTEGER>
Lookup: INTEGER
Define: <b:INTEGER>
Lookup: REAL
Define: <y:REAL>
Lookup: number
Lookup: a
Lookup: number
Lookup: b
Lookup: a
Lookup: number
Lookup: y
Symbol Table contents:
Symbols: [INTEGER, REAL, <number:INTEGER>, <a:INTEGER>, <b:INTEGER>, <y:REAL>]
Run-time GLOBAL_MEMORY contents:
a = 2
b = 25
number = 2
y = 5.99714285714
I’d like to draw your attention again to the fact that the Interpreter class has nothing to do with building the symbol table and it relies on the SymbolTableBuilder to make sure that the variables in the source code are properly declared before they are used by the Interpreter.
我想再次提醒大家注意这样一个事实,即 Interpreter 类与构建符号表无关,它依赖于 SymbolTableBuilder 来确保源代码中的变量在被 Interpreter 使用之前被正确声明。
Check your understanding
检查你的理解
- What is a symbol? 什么是符号?
某些程序实体(如变量、子例程或内置类型)的标识符
- Why do we need to track symbols? 为什么我们需要追踪符号?
- 为了确保在给变量赋值时,type是正确的(type检查)
- 确保在使用变量之前声明该变量。
- What is a symbol table? 什么是符号表?
符号表是一个用于追踪程序源代码中各种符号的抽象数据类型(ADT)
- What is the difference between defining a symbol and resolving/looking up the symbol? 定义一个符号和解析/查找这个符号有什么区别?
- 定义一个符号就是把该符号插入到符号表中,符号名作为键,符号实例作为值(值不再是Part9里的符号值了)。
- 解析/查找一个符号就是在符号表中通过符号名搜索这个符号,找到就返回符号实例,否则返回None。
方法 define 将符号作为参数,并将其存储在符号名作为键和符号实例作为值的 _symbols 有序字典中。方法 lookup 接受一个符号名作为参数,如果找到它就返回一个符号,如果找不到就返回“ None”。
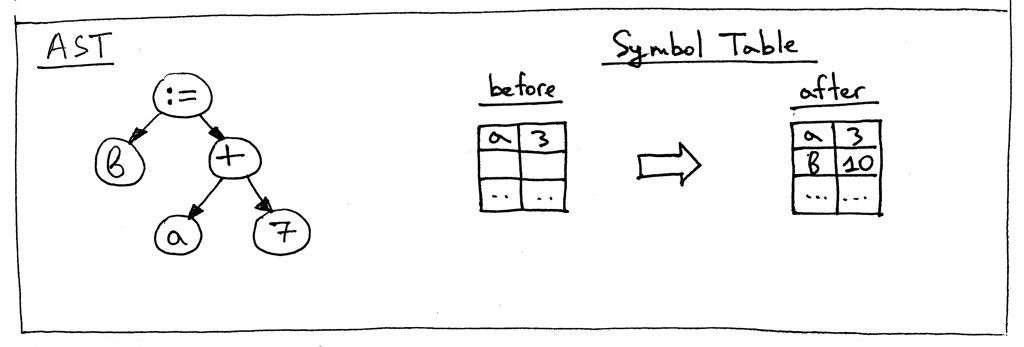
- Given the following small Pascal program, what would be the contents of the symbol table, the global memory (the GLOBAL_MEMORY dictionary that is part of the _Interpreter _) ?
给定下面的小 Pascal 程序,符号表和全局内存的内容是什么?(GLOBAL_MEMORY字典是解释器的一部分)?
PROGRAM Part11;
VAR
x, y : INTEGER;
BEGIN
x := 2;
y := 3 + x;
END.
符号表
| INTEGER | BuiltinTypeSymbol instance |
|---|---|
| REAL | BuiltinTypeSymbol instance |
| x | VarSymbol instance |
| y | VarSymbol instance |
全局内存
| x | 2 |
|---|---|
| y | 5 |
GLOBAL_MEMORY字典是解释器的一部分。
That’s all for today. In the next article, I’ll talk about scopes and we’ll get our hands dirty with parsing nested procedures. Stay tuned and see you soon! And remember that no matter what, “Keep going!”
今天就到这里吧。在下一篇文章中,我将讨论 域,并且我们将亲自操作解析嵌套过程。请继续关注,我们很快就会再见!记住,无论发生什么,“继续前进!”
get our hands dirty :弄脏手,所以真实意思就是:亲自动手操作。
P.S. My explanation of the topic of symbols and symbol table management is heavily influenced by the book Language Implementation Patterns by Terence Parr. It’s a terrific book. I think it has the clearest explanation of the topic I’ve ever seen and it also covers class scopes, a subject that I’m not going to cover in the series because we will not be discussing object-oriented Pascal.
附: 我对符号和符号表管理主题的解释深受 Terence Parr 的《语言实现模式》一书的影响。这是一本很棒的书。我认为它对我所见过的主题有最清晰的解释,它还涵盖了class的范围,这个主题我不打算在本系列中讨论,因为我们不会讨论面向对象的 Pascal。
P.P.S.: If you can’t wait and want to start digging into compilers, I highly recommend the freely available classic by Jack Crenshaw “Let’s Build a Compiler.”
附言: 如果你迫不及待想开始挖掘编译器,我强烈推荐 Jack Crenshaw 的免费经典作品“ Let’s Build a Compiler”
All articles in this series:
本系列的所有文章:
- Let's Build A Simple Interpreter. Part 1. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 2. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 3. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 4. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 5. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 6. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 7: Abstract Syntax Trees 让我们构建一个简单的解释器。第7部分: 抽象语法树
- Let's Build A Simple Interpreter. Part 8. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 9. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 10. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 11. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 12. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 13: Semantic Analysis 让我们建立一个简单的解释器。第13部分: 语义分析
- Let's Build A Simple Interpreter. Part 14: Nested Scopes and a Source-to-Source Compiler 让我们构建一个简单的解释器。第14部分: 嵌套作用域和源到源编译器
- Let's Build A Simple Interpreter. Part 15. 让我们构建一个简单的解释器。第15部分
- Let's Build A Simple Interpreter. Part 16: Recognizing Procedure Calls 让我们建立一个简单的解释器。第16部分: 识别过程调用
- Let's Build A Simple Interpreter. Part 17: Call Stack and Activation Records 让我们构建一个简单的解释器。第17部分: 调用堆栈和激活记录
- Let's Build A Simple Interpreter. Part 18: Executing Procedure Calls 让我们构建一个简单的解释器。第18部分: 执行过程调用
- Let's Build A Simple Interpreter. Part 19: Nested Procedure Calls 让我们构建一个简单的解释器。第19部分: 嵌套过程调用