Today we will continue closing the gap between where we are right now and where we want to be: a fully functional interpreter for a subset of Pascal programming language.
今天,我们将继续缩小我们现在所处的位置和我们想要达到的位置之间的差距: 一个用于 Pascal 编程语言子集的全功能解释器。
In this article we will update our interpreter to parse and interpret our very first complete Pascal program. The program can also be compiled by the Free Pascal compiler, fpc.
在本文中,我们将更新我们的解释器来解析和解释我们的第一个完整的 Pascal 程序。该程序也可以通过Free Pascal compiler, fpc 编译。
Here is the program itself:
下面是程序:
PROGRAM Part10;
VAR
number : INTEGER;
a, b, c, x : INTEGER;
y : REAL;
BEGIN {Part10}
BEGIN
number := 2;
a := number;
b := 10 * a + 10 * number DIV 4;
c := a - - b
END;
x := 11;
y := 20 / 7 + 3.14;
{ writeln('a = ', a); }
{ writeln('b = ', b); }
{ writeln('c = ', c); }
{ writeln('number = ', number); }
{ writeln('x = ', x); }
{ writeln('y = ', y); }
END. {Part10}
Before we start digging into the details, download the source code of the interpreter from GitHub and the Pascal source code above, and try it on the command line:
在我们开始深入研究细节之前,先从 GitHub 下载解释器的源代码和上面的 Pascal 源代码,然后在命令行上试一试:
$ python spi.py part10.pas
a = 2
b = 25
c = 27
number = 2
x = 11
y = 5.99714285714
If I remove the comments around the writeln statements in the part10.pas file, compile the source code with fpc and then run the produced executable, this is what I get on my laptop:
如果我删除 part10.pas 文件中 writeln 语句周围的注释,用 fpc 编译源代码,然后运行生成的可执行文件,这就是我在笔记本电脑上得到的结果:
$ fpc part10.pas
$ ./part10
a = 2
b = 25
c = 27
number = 2
x = 11
y = 5.99714285714286E+000
Okay, let’s see what we’re going cover today:
好的,让我们看看今天我们要学习什么:
- We will learn how to parse and interpret the Pascal _PROGRAM _ header
我们将学习如何解析和解释 Pascal PROGRAM header - We will learn how to parse Pascal variable declarations
我们将学习如何解析 Pascal 变量声明 - We will update our interpreter to use the DIV keyword for integer division and a forward slash / for float division
我们将更新我们的解释器以使用DIV关键字表示整数除法,斜杠/表示浮点除法 - We will add support for Pascal comments
我们将增加对 Pascal 注释的支持
Let’s dive in and look at the grammar changes first. Today we will add some new rules and update some of the existing rules. 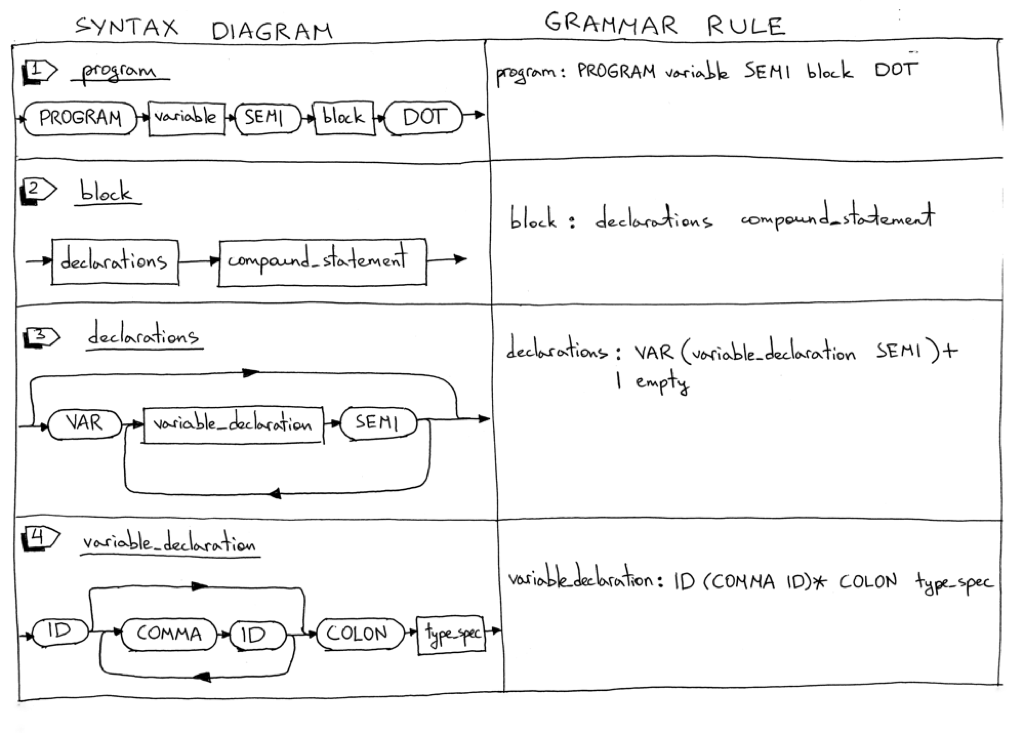
让我们先深入研究一下语法的变化。今天我们将添加一些新的规则并更新一些现有的规则。
- The program definition grammar rule is updated to include the PROGRAM reserved keyword, the program name, and a block that ends with a dot. Here is an example of a complete Pascal program:
_**program **_定义grammar规则被更新为包含 PROGRAM 保留关键字、程序名称和以点结尾的块。下面是一个完整的 Pascal 程序的例子:
PROGRAM Part10;
BEGIN
END.
- The block rule combines a declarations rule and a compound_statement rule. We’ll also use the rule later in the series when we add procedure declarations. Here is an example of a block:
block 规则结合了一个 _declarations _规则和一个 _compound_statement _规则。在本系列后面添加 procedure declarations 时,我们还将使用该规则。下面是一个 block 的例子:
VAR
number : INTEGER;
BEGIN
END
Here is another example:
下面是另一个例子:
BEGIN
END
- Pascal declarations have several parts and each part is optional. In this article, we’ll cover the variable declaration part only. The declarations rule has either a variable declaration sub-rule or it’s empty.
Pascal declarations 有几个部分,每个部分都是可选的。在本文中,我们将只讨论变量声明部分。声明规则要么有一个变量声明子规则,要么为空。 - Pascal is a statically typed language, which means that every variable needs a variable declaration that explicitly specifies its type. In Pascal, variables must be declared before they are used. This is achieved by declaring variables in the program variable declaration section using the VAR reserved keyword. You can define variables like this:
Pascal 是一种静态类型语言,这意味着每个变量都需要一个变量声明来明确指定它的类型。在 Pascal 语言中,变量在使用之前必须被声明。这是通过使用 VAR 保留关键字在程序变量声明部分中声明变量来实现的。你可以这样定义变量:
VAR
number : INTEGER;
a, b, c, x : INTEGER;
y : REAL;
- The type_spec rule is for handling INTEGER and REAL types and is used in variable declarations. In the example below
type_spec 规则用于处理 INTEGER 和 REAL 类型,并用于变量声明
VAR
a : INTEGER;
b : REAL;
the variable “a” is declared with the type INTEGER and the variable “b” is declared with the type REAL (float). In this article we won’t enforce type checking, but we will add type checking later in the series.
变量“ a”声明为 INTEGER 类型,变量“ b”声明为 REAL (float)类型。在本文中,我们不会强制执行类型检查,但是我们将在本系列的后面部分中添加类型检查。
- The term rule is updated to use the DIV keyword for integer division and a forward slash / for float division.
_**term **_规则更新为使用 DIV 关键字进行整数除法,使用正斜杠 / 进行浮点除法。
Before, dividing 20 by 7 using a forward slash would produce an INTEGER 2:
在此之前,20用正斜杠除以7会得到一个 INTEGER 2:
Now, dividing 20 by 7 using a forward slash will produce a REAL (floating point number) 2.85714285714 :
现在,用正斜杠除以20得到一个 REAL (浮点数)2.85714285714:
From now on, to get an INTEGER instead of a REAL, you need to use the DIV keyword:
从现在开始,为了得到一个 INTEGER 而不是 REAL,你需要使用 DIV 关键字: - The factor rule is updated to handle both integer and real (float) constants. I also removed the INTEGER sub-rule because the constants will be represented by INTEGER_CONST and REAL_CONST tokens and the INTEGER token will be used to represent the integer type. In the example below the lexer will generate an INTEGER_CONST token for 20 and 7 and a REAL_CONST token for 3.14 :
_**factor **_规则被更新以处理整数和实数(浮点数)常量。我还删除了 INTEGER 子规则,因为常量将由 INTEGER_CONST 和 REAL_CONST token表示,而 INTEGER token将用于表示整数类型。在下面的例子中,lexer 将为20和7生成一个 INTEGER_CONST token,为3.14生成一个 REAL_CONST token:
Here is our complete grammar for today:
以下是我们今天的完整语法:
program : PROGRAM variable SEMI block DOT
block : declarations compound_statement
declarations : VAR (variable_declaration SEMI)+
| empty
variable_declaration : ID (COMMA ID)* COLON type_spec
type_spec : INTEGER | REAL
compound_statement : BEGIN statement_list END
statement_list : statement
| statement SEMI statement_list
statement : compound_statement
| assignment_statement
| empty
assignment_statement : variable ASSIGN expr
empty :
expr : term ((PLUS | MINUS) term)*
term : factor ((MUL | INTEGER_DIV | FLOAT_DIV) factor)*
factor : PLUS factor
| MINUS factor
| INTEGER_CONST
| REAL_CONST
| LPAREN expr RPAREN
| variable
variable: ID
In the rest of the article we’ll go through the same drill we went through last time:
在本文的其余部分,我们将重复上次的操作:
- Update the lexer 更新 lexer
- Update the parser 更新解析器
- Update the interpreter 更新解释器
Updating the Lexer
Here is a summary of the lexer changes:
下面是 lexer 更改的摘要:
- New tokens
新的tokens - New and updated reserved keywords
新的和更新的保留关键字 - New _skip_comment _ method to handle Pascal comments
新的_skip_comment_方法来处理 Pascal 注释 - Rename the _integer _method and make some changes to the method itself
重命名 _integer _方法,并对方法本身进行一些更改 - Update the _get_next_token _ method to return new tokens
更新_get_next_token_方法以返回新的token
Let’s dig into the changes mentioned above:
让我们深入研究一下上面提到的变化:
- To handle a program header, variable declarations, integer and float constants as well as integer and float division, we need to add some new tokens - some of which are reserved keywords - and we also need to update the meaning of the INTEGER token to represent the integer type and not an integer constant. Here is a complete list of new and updated tokens:
为了处理程序头、变量声明、整数和浮点数常量以及整数和浮点数除法,我们需要添加一些新的token(其中一些是保留关键字) ,我们还需要更新 INTEGER token的含义,以表示整数类型,而不是整数常量。下面是新的和更新的token的完整列表:- PROGRAM (reserved keyword)
- VAR (reserved keyword)
- COLON (😃
- COMMA (,)
- INTEGER (we change it to mean integer type and not integer constant like 3 or 5)
- REAL (for Pascal REAL type)
- INTEGER_CONST (for example, 3 or 5)
- REAL_CONST (for example, 3.14 and so on)
- INTEGER_DIV for integer division (the DIV reserved keyword)
- FLOAT_DIV for float division ( forward slash / )
- Here is the complete mapping of reserved keywords to tokens:
下面是保留关键字到token的完整映射:
RESERVED_KEYWORDS = {
'PROGRAM': Token('PROGRAM', 'PROGRAM'),
'VAR': Token('VAR', 'VAR'),
'DIV': Token('INTEGER_DIV', 'DIV'),
'INTEGER': Token('INTEGER', 'INTEGER'),
'REAL': Token('REAL', 'REAL'),
'BEGIN': Token('BEGIN', 'BEGIN'),
'END': Token('END', 'END'),
}
- We’re adding the skip_comment method to handle Pascal comments. The method is pretty basic and all it does is discard all the characters until the closing curly brace is found:
我们添加了 skip_comment 方法来处理 Pascal 注释。这个方法非常简单,它所做的就是丢弃所有的字符,直到找到结束花括号:
def skip_comment(self):
while self.current_char != '}':
self.advance()
self.advance() # the closing curly brace
- We are renaming the integer method the number method. It can handle both integer constants and float constants like 3 and 3.14:
我们将 _integer _方法重命名为 number 方法。它可以处理整型常量和浮点型常量,比如3和3.14:
def number(self):
"""Return a (multidigit) integer or float consumed from the input."""
result = ''
while self.current_char is not None and self.current_char.isdigit():
result += self.current_char
self.advance()
if self.current_char == '.':
result += self.current_char
self.advance()
while (
self.current_char is not None and
self.current_char.isdigit()
):
result += self.current_char
self.advance()
token = Token('REAL_CONST', float(result))
else:
token = Token('INTEGER_CONST', int(result))
return token
- We’re also updating the get_next_token method to return new tokens:
我们还更新了 get_next_token 方法来返回新的令牌:
def get_next_token(self):
while self.current_char is not None:
...
if self.current_char == '{':
self.advance()
self.skip_comment()
continue
...
if self.current_char.isdigit():
return self.number()
if self.current_char == ':':
self.advance()
return Token(COLON, ':')
if self.current_char == ',':
self.advance()
return Token(COMMA, ',')
...
if self.current_char == '/':
self.advance()
return Token(FLOAT_DIV, '/')
...
Updating the Parser
更新解析器
Now onto the parser changes.
现在转到解析器更改上。
Here is a summary of the changes:
以下是这些变化的摘要:
- New AST nodes: Program, Block, VarDecl, Type
新的AST节点:Program, Block, VarDecl, Type - New methods corresponding to new grammar rules: block, declarations, variable_declaration, and type_spec.
对应新规则的新方法:block, declarations, variable_declaration, and _type_spec_ - Updates to the existing parser methods: program, term, and factor
更新现有的方法:program, term, and factor
Let’s go over the changes one by one:
让我们一个一个来看一下这些变化:
- We’ll start with new AST nodes first. There are four new nodes:
我们首先从新的 AST 节点开始,有四个新节点:- The Program AST node represents a program and will be our root node
Program AST 节点表示一个程序,将是我们的根节点
- The Program AST node represents a program and will be our root node
class Program(AST):
def __init__(self, name, block):
self.name = name
self.block = block
- The Block AST node holds declarations and a compound statement:
Block AST 节点包含声明和一个复合语句:
class Block(AST):
def __init__(self, declarations, compound_statement):
self.declarations = declarations
self.compound_statement = compound_statement
- The VarDecl AST node represents a variable declaration. It holds a variable node and a type node:
_VarDecl _AST 节点表示一个变量声明,它包含一个变量节点和一个类型节点:
class VarDecl(AST):
def __init__(self, var_node, type_node):
self.var_node = var_node
self.type_node = type_node
- The Type AST node represents a variable type (INTEGER or REAL):
Type AST 节点表示一个变量类型(INTEGER 或 REAL) :
class Type(AST):
def __init__(self, token):
self.token = token
self.value = token.value
- As you probably remember, each rule from the grammar has a corresponding method in our recursive-descent parser. Today we’re adding four new methods: block, declarations, variable_declaration, and type_spec. These methods are responsible for parsing new language constructs and constructing new AST nodes:
您可能还记得,在我们的递归下降分析器中,文法中的每个规则都有一个对应的方法。今天我们添加了四个新方法: block、 declaration、 variable_declaration 和 type_spec。这些方法负责解析新的语言结构并构造新的 AST 节点:
def block(self):
"""block : declarations compound_statement"""
declaration_nodes = self.declarations()
compound_statement_node = self.compound_statement()
node = Block(declaration_nodes, compound_statement_node)
return node
def declarations(self):
"""declarations : VAR (variable_declaration SEMI)+
| empty
"""
declarations = []
if self.current_token.type == VAR:
self.eat(VAR)
while self.current_token.type == ID:
var_decl = self.variable_declaration()
declarations.extend(var_decl)
self.eat(SEMI)
return declarations
def variable_declaration(self):
"""variable_declaration : ID (COMMA ID)* COLON type_spec"""
var_nodes = [Var(self.current_token)] # first ID
self.eat(ID)
while self.current_token.type == COMMA:
self.eat(COMMA)
var_nodes.append(Var(self.current_token))
self.eat(ID)
self.eat(COLON)
type_node = self.type_spec()
var_declarations = [
VarDecl(var_node, type_node)
for var_node in var_nodes
]
return var_declarations
def type_spec(self):
"""type_spec : INTEGER
| REAL
"""
token = self.current_token
if self.current_token.type == INTEGER:
self.eat(INTEGER)
else:
self.eat(REAL)
node = Type(token)
return node
- We also need to update the program, term, and, factor methods to accommodate our grammar changes:
我们还需要更新_program_、_term _和 factor 方法,以适应我们的语法变化:
def program(self):
"""program : PROGRAM variable SEMI block DOT"""
self.eat(PROGRAM)
var_node = self.variable()
prog_name = var_node.value
self.eat(SEMI)
block_node = self.block()
program_node = Program(prog_name, block_node)
self.eat(DOT)
return program_node
def term(self):
"""term : factor ((MUL | INTEGER_DIV | FLOAT_DIV) factor)*"""
node = self.factor()
while self.current_token.type in (MUL, INTEGER_DIV, FLOAT_DIV):
token = self.current_token
if token.type == MUL:
self.eat(MUL)
elif token.type == INTEGER_DIV:
self.eat(INTEGER_DIV)
elif token.type == FLOAT_DIV:
self.eat(FLOAT_DIV)
node = BinOp(left=node, op=token, right=self.factor())
return node
def factor(self):
"""factor : PLUS factor
| MINUS factor
| INTEGER_CONST
| REAL_CONST
| LPAREN expr RPAREN
| variable
"""
token = self.current_token
if token.type == PLUS:
self.eat(PLUS)
node = UnaryOp(token, self.factor())
return node
elif token.type == MINUS:
self.eat(MINUS)
node = UnaryOp(token, self.factor())
return node
elif token.type == INTEGER_CONST:
self.eat(INTEGER_CONST)
return Num(token)
elif token.type == REAL_CONST:
self.eat(REAL_CONST)
return Num(token)
elif token.type == LPAREN:
self.eat(LPAREN)
node = self.expr()
self.eat(RPAREN)
return node
else:
node = self.variable()
return node
Now, let’s see what the Abstract Syntax Tree looks like with the new nodes. Here is a small working Pascal program:
现在,让我们来看看使用这些新节点后的抽象语法树是什么样子的。下面是一个小型的 Pascal 程序:
PROGRAM Part10AST;
VAR
a, b : INTEGER;
y : REAL;
BEGIN {Part10AST}
a := 2;
b := 10 * a + 10 * a DIV 4;
y := 20 / 7 + 3.14;
END. {Part10AST}
Let’s generate an AST and visualize it with the genastdot.py:
让我们生成一个 AST,并用 genastdot.py 将其可视化:
$ python genastdot.py part10ast.pas > ast.dot && dot -Tpng -o ast.png ast.dot
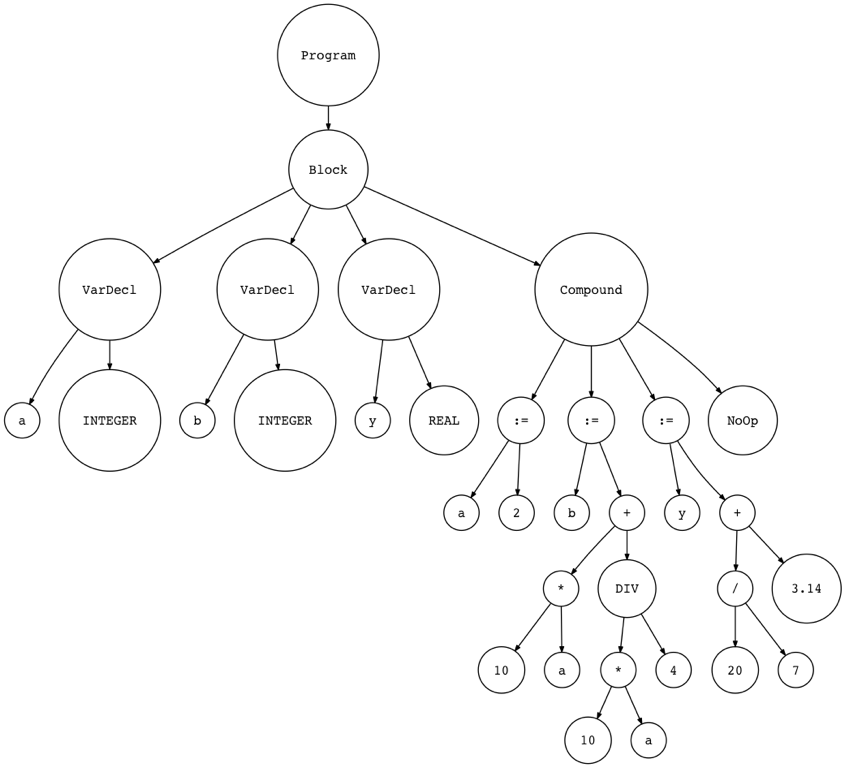
In the picture you can see the new nodes that we have added.
在图中可以看到我们添加的新节点。
Updating the Interpreter
更新解释器
We’re done with the lexer and parser changes. What’s left is to add new visitor methods to our Interpreter class. There will be four new methods to visit our new nodes:
我们已经完成了 lexer 和解析器的更改。剩下的工作是向我们的 Interpreter 类添加新的 visitor 方法。将有四种新方法访问我们的新节点:
- visit_Program
- visit_Block
- visit_VarDecl
- visit_Type
They are pretty straightforward. You can also see that the Interpreter does nothing with VarDecl and Type nodes:
你也可以看到 Interpreter 对 VarDecl 和 Type 节点什么也不做:
def visit_Program(self, node):
self.visit(node.block)
def visit_Block(self, node):
for declaration in node.declarations:
self.visit(declaration)
self.visit(node.compound_statement)
def visit_VarDecl(self, node):
# Do nothing
pass
def visit_Type(self, node):
# Do nothing
pass
We also need to update the visit_BinOp method to properly interpret integer and float divisions:
我们还需要更新 visit_BinOp 方法来正确解释整数和浮点数部分:
def visit_BinOp(self, node):
if node.op.type == PLUS:
return self.visit(node.left) + self.visit(node.right)
elif node.op.type == MINUS:
return self.visit(node.left) - self.visit(node.right)
elif node.op.type == MUL:
return self.visit(node.left) * self.visit(node.right)
elif node.op.type == INTEGER_DIV:
return self.visit(node.left) // self.visit(node.right)
elif node.op.type == FLOAT_DIV:
return float(self.visit(node.left)) / float(self.visit(node.right))
Let’s sum up what we had to do to extend the Pascal interpreter in this article:
让我们总结一下我们在本文中为扩展 Pascal 解释器所做的工作:
- Add new rules to the grammar and update some existing rules
- 向语法中添加新规则并更新一些现有规则
- Add new tokens and supporting methods to the lexer, update and modify some existing methods
- 向 lexer 添加新的token和支持方法,更新和修改一些现有的方法
- Add new AST nodes to the parser for new language constructs
- 添加新的AST节点到解析器以解析新语言结构
- Add new methods corresponding to the new grammar rules to our recursive-descent parser and update some existing methods
- 在我们的递归下降分析器中添加与新文法规则相对应的新方法,并更新一些现有的方法
- Add new visitor methods to the interpreter and update one existing visitor method
- 向解释器添加新的visitor方法并更新一个现有的visitor方法
As a result of our changes we also got rid of some of the hacks I introduced in Part 9, namely:
作为修改的结果,我们还删除了我在第9部分介绍的一些hacks,即:
- Our interpreter can now handle the **PROGRAM ** header
- 解释器现在可以处理_**PROGRAM **_ header
- Variables can now be declared using the VAR keyword
- 变量现在可以使用VAR关键字声明了
- The DIV keyword is used for integer division and a forward slash / is used for float division
- DIV 关键字用于整数除法,正斜杠/用于浮点除法
If you haven’t done so yet, then, as an exercise, re-implement the interpreter in this article without looking at the source code and use part10.pas as your test input file.
如果您还没有这样做,那么,作为练习,在本文中重新实现解释器,不要查看源代码,并使用 part10.pas 作为您的测试输入文件。
That’s all for today. In the next article, I’ll talk in greater detail about symbol table management. Stay tuned and see you soon!
今天就到这里吧。在下一篇文章中,我将更详细地讨论符号表管理。请继续关注,我们很快就会再见!
All articles in this series:
本系列的所有文章:
- Let's Build A Simple Interpreter. Part 1. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 2. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 3. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 4. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 5. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 6. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 7: Abstract Syntax Trees 让我们构建一个简单的解释器。第7部分: 抽象语法树
- Let's Build A Simple Interpreter. Part 8. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 9. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 10. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 11. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 12. 让我们构建一个简单的解释器
- Let's Build A Simple Interpreter. Part 13: Semantic Analysis 让我们建立一个简单的解释器。第13部分: 语义分析
- Let's Build A Simple Interpreter. Part 14: Nested Scopes and a Source-to-Source Compiler 让我们构建一个简单的解释器。第14部分: 嵌套作用域和源到源编译器
- Let's Build A Simple Interpreter. Part 15. 让我们构建一个简单的解释器。第15部分
- Let's Build A Simple Interpreter. Part 16: Recognizing Procedure Calls 让我们建立一个简单的解释器。第16部分: 识别过程调用
- Let's Build A Simple Interpreter. Part 17: Call Stack and Activation Records 让我们构建一个简单的解释器。第17部分: 调用堆栈和激活记录
- Let's Build A Simple Interpreter. Part 18: Executing Procedure Calls 让我们构建一个简单的解释器。第18部分: 执行过程调用
- Let's Build A Simple Interpreter. Part 19: Nested Procedure Calls 让我们构建一个简单的解释器。第19部分: 嵌套过程调用